CPP / C++ Notes - C++ Libraries Review
Table of Contents
- 1. C++ Libraries Review
- 1.1. GSL - Guideline Support Library (C++20)
- 1.2. mapbox variant
- 1.3. Range v3 (C++20)
- 1.4. Printf replacements
- 1.5. Pretty Printing
- 1.6. Command Line Parsing
- 1.7. Serialization
- 1.8. Parsers
- 1.9. Unit Testing
- 1.10. Google Benchmark
- 1.11. Pistache - REST Http Web Server
- 1.12. Httplib - Http Client and Server Library
1 C++ Libraries Review
1.1 GSL - Guideline Support Library (C++20)
1.1.1 Overview
The GSL - Guideline Support Library (not confused with GNU Scientific Library) contains implementations of some types and functions proposed by the C++ Core Guidelines for helping to enhance the code quality, reduce mistakes and make the intent clear. Note: some types of the C++ core guidelines such as std::span will be included in the C++20.
C++ Core Guidelines - Created by ISO C++ Comitee
- Site: https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines
- Repo: http://github.com/isocpp/CppCoreGuidelins
Implementations of the GSL Library
- Microsft's Implementation of the GSL (Most used)
- (First implementation of the Core Guideline Types)
- https://github.com/Microsft/GSL
- GSL-Lite - Single-header file implementation of the Microsft GSL (License: MIT)
- Martin Moene's GSL with Melanolib:
- Vicente Botet Escriba's fork:
Parts of GSL
- Views
- span<T>
- string_span<T>
- (cw) zstring
- Owners/Containers
- owner<T>
- unique_ptr<T> (for old compiler that does not support C++11)
- shared_ptr<T> (old compilers)
- dyn_array<T>
- stack_array<T>
- Utilities
- not_null<T>
- finally()
- Contract Support (Macros)
- Expect() => For pre-condition validation
- Ensure() => For post-condition validation
- Type casting conversions
- narrow()
- narrow_cast()
- Concepts
- String
- Number
- Sortable
- Pointer
Papers
- P0122R33 - span: bounds-safe views for sequences
- P0298R1 - A byte type definition
1.1.2 Type: gsl::owner
The type gsl::owner is proposed in the section I11 of the core guidelines:
- "I.11: Never transfer ownership by a raw pointer (T*) or reference (T&)"
Definition:
template <class T, class = std::enable_if_t<std::is_pointer<T>::value>> using owner = T;
The type owner<T> is just an alias for a pointer type for annotating raw owning pointer APIs that cannot be modified. This type allows distinguishing raw owning pointers from non-owning pointers, making the intent of the code clear.
See:
Before:
IBaseClass* factoryFunction(int key) { if(key == VALUE1) { return new Implementation1(arg1, arg2, ...); } if(key == VALUE1) { return new Implementation2; } // ... ... ... . // Invalid input return nullptr; }
After:
- The annotation gsl::owner<T> makes clear that pointer returned by factoryFunction owns memory and that it must release it later by calling the delete operator.
#include <gls/pointer> gsl::owner<IBaseClass*> factoryFunction(int key) { if(key == VALUE1) { return new Implementation1(arg1, arg2, ...); } if(key == VALUE1) { return new Implementation2; } // ... ... ... . // Invalid input return nullptr; } // --------- Usage: ------------------// int main() { std::cout << " Choose the implementation: "; int key; std::cin >> key; gsl::owner<IBaseClass*> object = factoryFunction(key); object->InvokeVirtualMemberFunction(); // ... ... ... .. delete object; }
1.1.3 Type: gsl::finally
The gsl::finally can register a callable object (lambda, functor or function pointer) which is called when it goes out of scope. This function is useful for exception-safe resource disposal or cleanup.
{ int* arr = new int [10]; // RAII => Calls lambda when this object is out-of-scope // and its destructor is called. auto scope_guard = gsl::finally( [=] { delete [] arr; std::puts("Resource cleaned OK."); }); for(size_t i = 0; i < 10; i++) { /** set arrary */ } } // scope_guard called here.
1.1.4 Functions: narrow_cast and narrow
The functions narrow and narrow_cast are used in several sections of the core guidelines, namely:
- ES.46: Avoid lossy (narrowing, truncating) arithmetic conversions
- ES.49: If you must use a cast, use a named cast
- P.4: Ideally, a program should be statically type safe
Function: narrow_cast()
- The function narrow_cast is equivalent to a static_cast operator, but it makes the clear and evident that a narrow cast is being performed, a casting from type to another with less bits, therefore with possible loss of information, loss of precision or overflow/undeflow error.
Usage:
#include <gls/gls> // Include all heders double xx = 105e4; // Same as static_cast, but the intent is more clear. Makes easier to // the reader spot that a loss of information or precision may happen. // // Note: If an underflow/overflow happens in this case, it is // undefined behavihor. UB int nx = gsl::narrow_cast<int>(xx);
Function: narrow()
- The function narrow<T>() is similar to the narrow_cast(), but it calls std::terminate or throws an exception if there is a loss of information in the narrow cast.
- The code in the next line throws a gsl::narrowing_error exception that abnormaly terminates the program because the value 10.535e10 when casted to int, results in an overflow, there is not enough bits to store the entire integer part of this number. This runtime check makes easier to catch bugs like this.
#include <gls/gls> // Include all heders double xx = 10.535e10; nx = gsl::narrow<int>(xx);
1.1.5 Type: gsl::span (C++20)
The GSL class gsl::span<T> (former gsl::array_view) is a non-owning representation or a view for a contiguous allocated sequence of objects which can be a std::vector; std::array<T, size_t>; zero-terminated C-string, a buffer represented by the tuple (pointer, size) or (C-array, size). The gsl::span<T> view can also be used for refactoring C-style functions that takes the tuple parameters (pointer, size), representing a buffer, and making the function safe against memory corruption, out-of-bound read/write and buffer overflows, which can introduce security vulnerabilities.
C++20 std::span documentation (not gsl::span)
Motivating Paper:
- P0122R3 - span: bounds-safe views for sequences of objects
Terminology:
- Non-owning: A gsl::span<T> object is not responsible for the allocating or releasing the objects that it points to.
- View: Object that encapsulates a reference type or points to existing objects that it does not own.
- Buffer: Any memory region represented by the pair (pointer, size), pointer to beginning of the region and buffer size.
Summary:
- gsl::span<T> can refer to any container: std::vector; std::array<T, size_t>; null-terminated character array; buffer, represented by pointer + tuple.
- gsl::span<T> does not allocate any memory and copying it does not copy any element, gsl:span<T> is a view.
Use-cases for gsl::span<T>:
- Provide range checking allowing to avoid buffer overrun (aka buffer overflow): terminates the program abnormally by calling std::terminate or throwing an exception (fail-fast approach). The range checking can be disabled for
- Creating functions that can take std::vector, std::aray or a buffer which can be presented by a C-style aray or the pair (pointer, size).
- Refactoring: Make C-style functions that take a buffer parameter represented by the pair (pointer, size) safer against buffer overflow vulnerabilities. The view object gsl::span<T> has built-in array-bound checking, any out-of-bounds access can either throw a gsl::fail_fast exception or a call std::terminate terminating the program abnormally.
Constructors
// --------- Constructors for dynamic-size span -----------// gls::span(); gsL::span(nullptr_t) noexcept; gls::span(pointer ptr, index_type number_of_elements); gls::span(pointer ptrFirstElement, ptrLastElement); template <class Container> gls::span(Container& container); // --------- Constructors for fixed-size span ---------------// // Array buffer of size N. i.e: int array [10] = { 1, 2, ..., 10}; template <size_t N> gsl::span(element_type (&array) [N]); template <size_t N> gsl::span(Container& container); template <size_t N> gsl::span(Container const& container);
Memeber Functions
| Return | Function | Description | |
|---|---|---|---|
| Type | |||
| A | index_type | size() const | Returns number of elements in the span |
| B | index_type | size_bytes() const | Returns the total size of sequence in bytes |
| C | TElement* | data() const | Returns pointer to first element of span. |
| D | bool | empty() const | Returns treu if the span is empty |
| E | TElement& | operator[](index_type idx) const | Returns reference to idx-th element of span. |
| F | TElement& | at(index_type idx) const | Returns reference to idx-th element of span. |
| G | gsl::span | subspan(index_type offset, index_count n) | Obtains a new span view from offset to (offset + n) elements. |
| H | iterator | being() const | Returns iterator to beginning of span. |
| I | iterator | end() const | Returns iterator to end of span. |
| J | const_iterator | cbegin() const | |
| L | cosnt_iterator | cend() const | |
- Note: E => The behavior of the operator (operator[])(index_type ) is undefined if idx index is out of range.
- Note: F => Throws an exception if the index idx is out of range.
Dynamic-size gsl::span assignment
- The variable sp of type gsl::span<int> can refere to fixed-size array; std::vector<int>; std::array<int, size_t> and so on.
- assert(<PREDICATE>) => Terminates the program abnormally by calling std::abort if the predicate is false, then shows an error message indicating the file and line where the assertion has failed.
gsl::span<int> sp; //--------- assign C-array to span -------------- // int carr [] = {-15, 6, 10, 9, 200}; sp = xs; // sp refers to array xs assert(sp[2] == 10); assert(sp[3] == 9); assert(sp.size() == 5); assert() //------ Assign fixed-size buffer (C-array) to span ---// int buffer[200] = {3, 5, 6, 10, 20}; sp = buffer; assert(sp.size() == 200); assert(sp[2] == 6); assert(sp[0] == 3); //---- Assign to buffer defined by (pointer, size) tuple to span ---// int* p_buffer = &carr; auto buffer_size = gsl::index(5); sp = gsl::make_span(p_buffer, buffer_size); assert(sp.size() == 5); assert(sp[0] == -15); assert(sp[2] == 10); //------ assign std::vector cointainer to span -------// std::vector<int> xs = {1, 2, 3, 4, 5}; sp = xs; // sp refers to vector xs assert(sp[2] == 3); assrrt(sp.size() == 5); //------ assign std::array to span -------------------// std::array<int, 6> arr = {10, 20, 30, 40, 50, 60}; sp = arr; // sp refers to std::array arr assert(sp[2] == 30); assert(sp.size() == 6)
Looping over gsl::span<T>
Dataset definition:
int dataset [] = {200, 100, -90, 89, 610, 53, 1365}; std::span<int> arrview; arrview = dataset;
Index-based loop:
for(auto idx = gsl::index(0); idx < arr.size(); ++idx) { std::cout << " Element[" << idx << "] =" << arrview[idx] << "\n"; }
Iterator-based loop:
for(auto it = arrview.begin(); it != arrview.end(); ++it) { std::cout << *it << std::endl; }
Iterator-based loop using std::begin() and std::end() functions:
for(auto it = std::begin(arrview); it != std::end(arrview); ++it) { std::cout << *it << std::endl; }
Range-based loop:
for(auto const& x: arrview) { std::cout << x << "\n"; }
Iteration with STL algorithms (header <algorithm>)
std::for_each(arrview.begin(), arrview.end(), [](int n) { std::cout << n << "\n"; }); std::sort(arrview.begin(), arrview.end());
Function with gsl::span argument
A function that uses gsl::span<T> as argument can accept any buffer, C-arrray or continguous container as input.
int sum_span_element(gsl::span<int> xs) { int sum = 0; for(auto x: xs){ sum += x; } return sum; } gsl::span<int> sp; // ------ Passing a C-array argument ------------------------------// int carr [] = {-15, 6, 10, 9, 200}; sp = carr; assert(sum_span_element(carr) == 210); assert(sum_span_element(sp) == 210); // ----- Passing a buffer argument defined by (pointer, size) pair ---// int* buffer_ptr = carr; // Address of carr[0] int buffer_size = 5; sp = gsl::make_span(buffer_ptr, buffer_size); assert( sum_span_element(sp) == 210 ); assert( sum_span_element(gsl::make_span(buffer_ptr, gsl::index(buffer_size))) == 210 ); assert( sum_span_element({buffer_ptr, gsl::index(buffer_size)}) == 210 ); // ---- Passing a std::vector argument ------------------// std::vector<int> vec = {10, 256, -15, 20, -8}; sp = vec; assert( sum_span_element(sp) == 263 ); assert( sum_span_element(vec) == 263 );
1.1.6 gsl::span code example
File: CMakeLists.txt
cmake_minimum_required(VERSION 3.14) project(gls_experiment) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) # See documentation at: https://cmake.org/cmake/help/latest/module/FetchContent.html #========== Macros for automating Library Fetching =============# include(FetchContent) # Download library archive (zip, *.tar.gz, ...) from URL macro(Download_Library_Url NAME URL) FetchContent_Declare(${NAME} URL ${URL}) FetchContent_GetProperties(${NAME}) message( [DOWNLOAD LIB] " VAR1 = ${${NAME}_SOURCE_DIR}") if(NOT ${NAME}_POPULATED) FetchContent_Populate(${NAME}) add_subdirectory(${${NAME}_SOURCE_DIR} ${${NAME}_BINARY_DIR}) endif() endmacro() #============== Library Download =========================# Download_Library_Url( gsl https://github.com/microsoft/GSL/archive/v2.0.0.zip ) # ========= Targets Settings ==========================# add_executable(microsft_gsl microsft_gsl.cpp) target_link_libraries(microsft_gsl GSL)
File: gsl_span1.cpp
#include <iostream> #include <iomanip> #include <memory> #include <vector> #include <array> #include <algorithm> #include <numeric> // #define GSL_UNENFORCED_ON_CONTRACT_VIOLATION // #define GSL_TERMINATE_ON_CONTRACT_VIOLATION #define GSL_THROW_ON_CONTRACT_VIOLATION // ------ Headers from the GSL - Guideline Support Library ----------// //-------------------------------------------------------------------// //#include <gsl/gsl> // For including everything #include <gsl/gsl> #include <gsl/span> #include <gsl/pointers> void display_span(const char* name, gsl::span<int> xs) { std::cout << " => " << name << " = [ "; for(auto const& x: xs){ std::cout << x << ", "; } std::cout << " ]\n"; } template<typename T> void disp(const char* label, T&& value) { std::cout << std::setw(5) << " =>> " << std::setw(10) << label << std::setw(4) << "=" << std::setw(6) << value << std::endl; } int cstring_len(gsl::not_null<const char*> ptr) { int n = 0; for(auto p = ptr.get(); *p != '\0'; ++p) n++; return n; } int main() { std::puts("\n ==== EXPERIMENT 1 - gsl::span variable =====================\n"); { // Variable span, non owning view that can refere to any contiguous memory, // C-array buffers; buffers (pointer, size) tuple; std::vector; std::array gsl::span<int> sp; int carray [] = {10, 5, 8, 5, 6, 15}; sp = carray; int* ptr_data = sp.data(); display_span("carray [A]", sp); display_span("carray [B]", carray); disp(" *(carray.data + 0) ", *ptr_data); disp(" *(carray.data + 0) ", *(ptr_data + 1)); // Display buffer defined by tuple (pointer, size) int* buffer_ptr = carray; size_t buffer_size = std::size(carray); sp = gsl::make_span(buffer_ptr, buffer_size); display_span("buffer", sp); std::vector<int> vector1 = {10, 256, -15, 20, -8}; sp = vector1; // View refers to vector1 display_span("vector1 [A]", sp); display_span("vector1 [B]", sp); // Just a nice C++ wrapper for a C stack-allocated or static-allocated array // It encapsulates the array: int [] std_array = {100, ...} std::array<int, 7> std_array = {100, -56, 6, 87, 61, 25, 151}; sp = std_array; display_span("std_array [A]", sp); display_span("std_array [B]", sp); } std::puts("\n ==== EXPERIMENT 2 - gsl::span with std algorithms ======\n"); { int carray [] = {8, 10, 5, 90, 0, 14}; gsl::span<int> sp; sp = carray; display_span("carray <before>", sp); std::sort(sp.begin(), sp.end()); display_span("carray <after>", sp); auto sum = std::accumulate(sp.begin(), sp.end(), 0); std::cout << " [INFO] sum of all elements = " << sum << std::endl; } std::puts("\n ==== EXPERIMENT 3 - gsl::span methods ==================\n"); { int carrayA [] = {10, 15, -8, 251, 56, 15, 100}; auto sp = gsl::span{carrayA}; std::cout << std::boolalpha; // Returns true if the view points to an empty location disp("sp.empty()", sp.empty()); // Returns the number of elements disp("sp.size()", sp.size()); // Returns the total size in bytes disp("sp.size_byte()", sp.size_bytes()); // --- Access to elements with array-index operator [] -------// // Note: The bound checking only happens in the debug build. // In the release build, it is disabled. disp("sp[0]", sp[0]); disp("sp[4]", sp[4]); disp("sp[5]", sp[5]); sp[0] = 100; // ---- Access to elements with always enabled, throws exception // if the access is out of bounds. disp("sp.at(0)", sp.at(0)); disp("sp.at(4)", sp.at(5)); disp("sp.at(5)", sp.at(4)); // Note 1: The bound checking with array operator is only enabled // for debug building, in the release building it can be disabled // due to performance reasons. // // Note 2: It only throws exception, if the macro // GSL_THROW_ON_CONTRACT_VIOLATION is defined before GSL includes. // Otherwise, it calls std::terminate without throwing an exception. try { disp("sp[15]", sp[15]); } catch (gsl::fail_fast& ex) { std::cout << " [ERROR] Failure = " << ex.what() << std::endl; } } return 0; }
Output:
==== EXPERIMENT 1 - gsl::span variable ===================== => carray [A] = [ 10, 5, 8, 5, 6, 15, ] => carray [B] = [ 10, 5, 8, 5, 6, 15, ] =>> *(carray.data + 0) = 10 =>> *(carray.data + 0) = 5 => buffer = [ 10, 5, 8, 5, 6, 15, ] => vector1 [A] = [ 10, 256, -15, 20, -8, ] => vector1 [B] = [ 10, 256, -15, 20, -8, ] => std_array [A] = [ 100, -56, 6, 87, 61, 25, 151, ] => std_array [B] = [ 100, -56, 6, 87, 61, 25, 151, ] ==== EXPERIMENT 2 - gsl::span with std algorithms ====== => carray <before> = [ 8, 10, 5, 90, 0, 14, ] => carray <after> = [ 0, 5, 8, 10, 14, 90, ] [INFO] sum of all elements = 127 ==== EXPERIMENT 3 - gsl::span methods ================== =>> sp.empty() = false =>> sp.size() = 7 =>> sp.size_byte() = 28 =>> sp[0] = 10 =>> sp[4] = 56 =>> sp[5] = 15 =>> sp.at(0) = 100 =>> sp.at(4) = 15 =>> sp.at(5) = 56 [ERROR] Failure = GSL: Precondition failure at ... .../_deps/gsl-src/include/gsl/span: 499
1.2 mapbox variant
Mapbox variant is a C++14,C++11 header-only library which provides variant type which are discriminant union containers (sum types), also called as algebraic data types in functional programming languages.
Repository:
Benefits:
- Supports C++11 and C++14 compilers
- Header only, however with fast compile-time.
- Similar to Boost.Variant (unlike std::variant which is stack-allocated), but it is more convenient to use than Boost.Variant as the only way to get it is downloading and installing the whole Boost library.
- Unlike, std::variant from C++17, which are stack allocated, mapbox variant can deal with non-complete recursive types as it is heap-allocated. In other words it can deal with recursive types without explicitly using std::unique_ptr, std::shared_ptr and so on.
Use cases:
- Traverse recursive data structures, for instance: AST - Abstract Syntax Trees; Trees; Binary Trees; Json; XML; …;
- Implement visitor object oriented design pattern.
- Implement double dispatching.
- Evaluate ASTs - Abstract Syntax Trees.
- Emulate algebraic data types from functional programming languages.
- Emulate pattern matching from functional programming languages.
- Implementation of compilers, interpreters and parsers.
Sample Code
GIST:
File: CMakeLists.txt
cmake_minimum_required(VERSION 3.9) project(recursive-variant) #========== Global Configurations =============# #----------------------------------------------# set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) set(CMAKE_CXX_EXTENSIONS OFF) # ------------ Download CPM CMake Script ----------------# ## Automatically donwload and use module CPM.cmake file(DOWNLOAD https://raw.githubusercontent.com/TheLartians/CPM.cmake/v0.26.2/cmake/CPM.cmake "${CMAKE_BINARY_DIR}/CPM.cmake") include("${CMAKE_BINARY_DIR}/CPM.cmake") #----------- Add dependencies --------------------------# CPMAddPackage( NAME mapbox-variant URL https://github.com/mapbox/variant/archive/v1.1.6.zip DOWNLOAD_ONLY YES ) include_directories( ${mapbox-variant_SOURCE_DIR}/include ) message([TRACE] " mapbox source = ${mapbox-variant_SOURCE_DIR} ") #----------- Set targets -------------------------------# add_executable(app1 app1.cpp) target_link_libraries(app1)
File: app1.cpp
#include <iostream> #include <string> #include <sstream> #include <cassert> #include <mapbox/variant.hpp> namespace m = mapbox::util; // Forward declarations struct Add; struct Mul; using expr = m::variant<int, m::recursive_wrapper<Add>, m::recursive_wrapper<Mul>>; struct Add { expr lhs; expr rhs; Add(expr lhs, expr rhs): lhs(lhs), rhs(rhs){ } }; struct Mul { expr lhs; expr rhs; Mul(expr lhs, expr rhs): lhs(lhs), rhs(rhs){ } }; struct EvalVisitor { int operator()(int x) { return x; } int operator()(Add const& v) { return m::apply_visitor(*this, v.lhs) + m::apply_visitor(*this, v.rhs); } int operator()(Mul const& v) { return m::apply_visitor(*this, v.lhs) * m::apply_visitor(*this, v.rhs); } }; struct StringVisitor { std::string format_expr(expr node) { if(node.is<int>()) return std::to_string( node.get<int>() ); else return std::string() + " (" + m::apply_visitor(*this, node) + ") "; } std::string operator()(int x) { return std::to_string(x); } std::string operator()(Add const& v) { return this->format_expr(v.rhs) + " + " + this->format_expr(v.lhs); } std::string operator()(Mul const& v) { return this->format_expr(v.rhs) + " * " + this->format_expr(v.lhs); } }; int main(int argc, char** argv) { std::cout << " [INFO] Running Ok " << std::endl; std::cout << std::boolalpha; // Abstract syntax tree expr ast; // Create visitor object auto eval = EvalVisitor{}; auto disp = StringVisitor{}; ast = 10; std::cout << " =>> is_num? = " << ast.is<int>() << "\n"; std::cout << " =>> value = " << ast.get<int>() << "\n"; std::cout << " =>> Expr 0 = " << m::apply_visitor(disp, ast) << "\n"; std::cout << " =>> Result 0 = " << m::apply_visitor(eval, ast) << '\n'; ast = Mul(5, Add(3, 4)); std::cout << "\n"; std::cout << " =>> is_num? = " << ast.is<int>() << "\n"; std::cout << " =>> is_add? = " << ast.is<Mul>() << "\n"; std::cout << " =>> Expr 1 = " << m::apply_visitor(disp, ast) << "\n"; std::cout << " =>> Result 1 = " << m::apply_visitor(eval, ast) << '\n'; // (10 + 4) * (5 * (3 + 8)) = 770 ast = Mul(Add(10, 4), Mul(5, Add(3, 8))); std::cout << "\n"; std::cout << " =>> is_mul? = " << ast.is<Mul>() << "\n"; std::cout << " =>> Expr 2 = " << m::apply_visitor(disp, ast) << "\n"; int result = m::apply_visitor(eval, ast); assert(result == 770); std::cout << " =>> Result 2 = " << result << '\n'; return 0; }
Output:
[INFO] Running Ok =>> is_num? = true =>> value = 10 =>> Expr 0 = 10 =>> Result 0 = 10 =>> is_num? = false =>> is_add? = true =>> Expr 1 = (4 + 3) * 5 =>> Result 1 = 35 =>> is_mul? = true =>> Expr 2 = ( (8 + 3) * 5) * (4 + 10) =>> Result 2 = 770
1.3 Range v3 (C++20)
Ranges v3 is a header-only generic library that will be included in the C++20 ranges and provides stl-like algorithms that can operate on ranges, also known as pairs of iterators. The benefit of the range v3 library over STL algorithms and iterator pairs is that the greater composability and that the calling code does not need to specify the iterator pair explicitly.
Resources:
- Documentation:
- Conan Reference:
- Github Repsitory:
- C++ Standard Proposal:
- C++20 - <ranges> header
- Videos:
Headers:
- Include all features:
- <range/v3/all.hpp> (Note: It increase the compile-time)
- Algorithms
- <range/v3/action/join.hpp>
- <range/v3/algorithm/copy.hpp>
- <range/v3/algorithm/for_each.hpp>
- <range/v3/algorithm/mismatch.hpp>
- All
- <range/v3/view/transform.hpp>
- <range/v3/core.hpp>
- <range/v3/view/all.hpp>
- <range/v3/view/concat.hpp>
- <range/v3/view/group_by.hpp>
- <range/v3/view/iota.hpp>
- <range/v3/view/join.hpp>
- <range/v3/view/repeat_n.hpp>
- <range/v3/view/single.hpp>
- <range/v3/view/take.hpp>
- <range/v3/view/transform.hpp>
Built-in Range Views:
- Views are lazily evaluated algorithms that are computed on demand without any wasteful allocation.
| adjacent_remove_if | drop_while | map | split |
| all | empty | move | stride |
| any_range | filter | parital_sum | tail |
| bounded | for_each | remove_if | take |
| c_str | generate | repeat | take_exactly |
| chunck | generate_n | repetat_n | take_while |
| concat | group_by | replace | tokenize |
| const_ | indirect | replace_if | transform |
| counted | interspece | reverse | unbounded |
| delimit | iota | single | unique |
| drop | join | slice | zip_with |
Built-in Range Actions:
- Actions are eager sequence algorithms that operates on containers and returns containers.
| drop | push_front | stable_sort |
| drop_while | remove_if | stride |
| erase | shuffle | take |
| insert | slice | take_while |
| join | sort | transform |
| push_back | split | unique |
Comparison Range Views X Range Actions:
| Range Views | Range Actions |
|---|---|
| Lazy sequence algorithms | Eager sequence algorithms |
| Lightweightm, non owning | Operates on containers and returns containers. |
| Doesn't perform allocation | Performs allocation |
| Composable | Composable |
| Non-mutating | Potentially mutating |
Example:
- Complete source:
Main Function - Range Algorithms Experiments
- Experiment 1A:
std::cout << " +------------------------------------+\n" << " | Range Algorithms Experiments |\n" << " +------------------------------------+\n"; auto printLambda = [](auto x){ std::cout << " x = " << x << std::endl; }; // std::cout << view::iota(2, 10) << std::endl; //-------------------------------------------// std::puts("\n === EXPERIMENT 1 A - for_each ==="); { std::vector<int> xs = {8, 9, 20, 25}; std::cout << " => Print numbers" << std::endl; ranges::for_each(xs, printLambda); std::deque<std::string> words = {"c++", "c++17", "C++20", "asm", "ADA"}; std::cout << " => Print words" << std::endl; ranges::for_each(xs, printLambda); }
Output:
+------------------------------------+ | Range Algorithms Experiments | +------------------------------------+ === EXPERIMENT 1 A - for_each === => Print numbers x = 8 x = 9 x = 20 x = 25 => Print words x = 8 x = 9 x = 20 x = 25
- Experiment 1B
std::puts("\n === EXPERIMENT 1 B - for_each ==="); { std::string astr = "bolts"; ranges::for_each(astr, printLambda); }
Output:
=== EXPERIMENT 1 B - for_each === x = b x = o x = l x = t x = s
- Experiment 2
std::puts("\n === EXPERIMENT 2 - sort ==="); { std::vector<double> xs2 = {10.45, -30.0, 45.0, 8.2, 100.0, 10.6}; std::cout << " Reverse vector" << std::endl; std::cout << " BEFORE xs2 = " << xs2 << std::endl; ranges::sort(xs2); std::cout << " AFTER xs2 = " << xs2 << std::endl; }
Output:
=== EXPERIMENT 2 - sort === Reverse vector BEFORE xs2 = [6]( 10.45 -30 45 8.2 100 10.6 ) AFTER xs2 = [6]( -30 8.2 10.45 10.6 45 100 )
- Experiment 3
std::puts("\n === EXPERIMENT 3 - fill ==="); { std::vector<int> xs2(10, 0); std::cout << " BEFORE A xs2 = " << view::all(xs2 )<< std::endl; std::cout << " BEFOREB B xs2 = " << xs2 << std::endl; ranges::fill(xs2, 10); std::cout << " AFTER 1 => x2 = " << xs2 << std::endl; ranges::fill(xs2, 5); std::cout << " AFTER 2 => x2 = " << xs2 << std::endl; }
Output:
=== EXPERIMENT 3 - fill === BEFORE A xs2 = [0,0,0,0,0,0,0,0,0,0] BEFOREB B xs2 = [10]( 0 0 0 0 0 0 0 0 0 0 ) AFTER 1 => x2 = [10]( 10 10 10 10 10 10 10 10 10 10 ) AFTER 2 => x2 = [10]( 5 5 5 5 5 5 5 5 5 5 )
- Experiment 4:
std::puts("\n === EXPERIMENT 4 - reverse ==="); { std::deque<std::string> words = {"c++", "c++17", "C++20", "asm", "ADA"}; std::cout << " BEFORE => words = " << view::all(words) << std::endl; ranges::reverse(words); std::cout << " AFTER => words = " << view::all(words) << std::endl; }
Output:
=== EXPERIMENT 4 - reverse === BEFORE => words = [c++,c++17,C++20,asm,ADA] AFTER => words = [ADA,asm,C++20,c++17,c++]
- Experiment 5:
std::puts("\n === EXPERIMENT 5 - remove_if ==="); { std::vector<int> xvec = {1, 2, 5, 10, 1, 4, 1, 2, 8, 20, 100, 10, 1}; std::cout << " BEFORE => xvec = " << xvec << std::endl; // Erase remove idiom xvec.erase(ranges::remove_if(xvec, [](int x){ return x == 1; }), xvec.end()); std::cout << " AFTER => xvec = " << xvec << std::endl; }
Output:
=== EXPERIMENT 5 - remove_if === BEFORE => xvec = [13]( 1 2 5 10 1 4 1 2 8 20 100 10 1 ) AFTER => xvec = [9]( 2 5 10 4 2 8 20 100 10 )
- Experiment 6:
std::puts("\n === EXPERIMENT 6 - find ==="); { std::vector<int> xvec = {1, 2, 5, 10, 1, 4, 1, 2}; auto it = ranges::find(xvec, 10); if(it != xvec.end()){ std::cout << " [OK] Found value == 10 => *it = " << *it << std::endl; std::cout << " Position = " << ranges::distance(xvec.begin(), it) << std::endl; } else std::cout << " [FAIL] Not found value " << std::endl; }
Output:
=== EXPERIMENT 6 - find === [OK] Found value == 10 => *it = 10 Position = 3
- Experiment 7:
std::puts("\n === EXPERIMENT 7 - accumulator ==="); { std::vector<int> xvec = {1, 2, 5, 10, 1, 4, 1, 2}; int result = ranges::accumulate(xvec, 0); std::cout << " => ranges::accumulate(xvec, 0) = " << result << std::endl; }
Output:
=== EXPERIMENT 7 - accumulator === => ranges::accumulate(xvec, 0) = 26
Range View Experiments
- Experiment 1A
std::cout << "\n"; std::cout << " +------------------------------------+\n" << " | Range View Experiments |\n" << " +------------------------------------+\n"; std::puts("\n === EXPERIMENT 1A - view::all"); { std::vector<char> xs = {'x', 'y', 'm', 'k', 'm'}; std::cout << " [1] => std::view(xs) = " << view::all(xs) << std::endl; std::cout << "\n [2] => xs = "; for(auto&& x: view::all(xs)) std::cout << x << " "; std::cout << std::endl; }
Output:
=== EXPERIMENT 1A - view::all [1] => std::view(xs) = [x,y,m,k,m] [2] => xs = x y m k m
- Experiment 1B
std::puts("\n === EXPERIMENT 1B - view::reverse ==="); { std::vector<char> xs = {'x', 'y', 'm', 'k', 'm'}; for(auto const& x: view::reverse(xs)) std::cout << " " << x; std::cout << std::endl; std::cout << " AFTER xs = " << xs << std::endl; }
Output:
=== EXPERIMENT 1B - view::reverse === m k m y x AFTER xs = [5]( x y m k m )
- Experiment 1C:
std::puts("\n === EXPERIMENT 1C - view::transform ==="); { std::vector<int> xs = {100, 5, 20, 9, 10, 6}; auto a_lambda = [](auto x){ return 5 * x -10; }; for(auto const& x: xs | view::transform(a_lambda)) std::cout << " " << x; std::cout << std::endl; //std::cout << " AFTER xs = " << xs << std::endl; }
Output:
=== EXPERIMENT 1C - view::transform === 490 15 90 35 40 20
- Experiment 2A:
std::puts("\n === EXPERIMENT 2A - Range adaptors pipeline ==="); { auto a_lambda = [](auto x){ return 5 * x -10; }; std::cout << " => Iota view = "; for(auto const& x: view::iota(1) | view::take(8)) std::cout << " " << x; std::cout << std::endl; }
Output:
=== EXPERIMENT 2A - Range adaptors pipeline === => Iota view = 1 2 3 4 5 6 7 8
- Expeirment 2B
std::puts("\n === EXPERIMENT 2B - Range adaptors pipeline ==="); { std::cout << " => Iota view [B] = \n"; auto aview = view::iota(1) | view::take(5) | view::transform([](int x){ return 5 * x + 6; }); std::cout << " [INFO] aview = " << aview << std::endl; std::cout << " [INFO] aview | reverse = " << (aview | view::reverse) << std::endl; std::cout << "\n Iteration 1 => "; ranges::for_each(aview, [](int a){ std::cout << a << " "; }); std::cout << "\n Iteration 2 => "; for(auto const& x: aview | view::reverse) std::cout << x << " "; std::cout << std::endl; }
Output:
=== EXPERIMENT 2B - Range adaptors pipeline === => Iota view [B] = [INFO] aview = [11,16,21,26,31] [INFO] aview | reverse = [31,26,21,16,11] Iteration 1 => 11 16 21 26 31 Iteration 2 => 31 26 21 16 11
- Experiment 3A
std::puts("\n === EXPERIMENT 3A - enumerate ==="); { std::deque<std::string> words = { "c++", "c++17", "C++20", "asm" }; std::cout << " ==== Loop 1 ==== " << std::endl; for(auto const& x: view::enumerate(words)) std::cout << " => n = " << x.first << " ; w = " << x.second << std::endl; std::cout << " ==== Loop 2 ==== " << std::endl; for(auto const& x: words | view::enumerate) std::cout << " => n = " << x.first << " ; w = " << x.second << std::endl; }
Output:
=== EXPERIMENT 3A - enumerate === ==== Loop 1 ==== => n = 0 ; w = c++ => n = 1 ; w = c++17 => n = 2 ; w = C++20 => n = 3 ; w = asm ==== Loop 2 ==== => n = 0 ; w = c++ => n = 1 ; w = c++17 => n = 2 ; w = C++20 => n = 3 ; w = asm
- Experiment 4A:
std::puts("\n === EXPERIMENT 4 - ranges::accumulate withe iterator ==="); { auto aview = view::iota(2) | view::transform([](double x){return 3.0 * x - 5; }) | view::take(15); std::cout << " aview = " << aview << std::endl; std::cout << " accumulate(aview) = " << ranges::accumulate(aview, 0.0) << std::endl; }
Output:
=== EXPERIMENT 4 - ranges::accumulate withe iterator === aview = [1,4,7,10,13,16,19,22,25,28,31,34,37,40,43] accumulate(aview) = 330
- Experiment 5
std::puts("\n === EXPERIMENT 5 - Copy Range to destination ==="); { std::vector<int> output; auto aview = view::iota(5) | view::transform([](int n){ return 6 * n - 10;}) | view::take(10); std::cout << " BEFORE => output = " << output << std::endl; ranges::copy(aview, ranges::back_inserter(output)); std::cout << " AFTER => output = " << output << std::endl; }
Output:
=== EXPERIMENT 5 - Copy Range to destination === BEFORE => output = [0]( ) AFTER => output = [10]( 20 26 32 38 44 50 56 62 68 74 )
1.4 Printf replacements
1.4.1 fmtlib (fmt) - Better printf (C++20)
Fmt is a highly popular library for printing in similar way to the old C's printf. The advantage of fmt over old printf are the type safety and concise format specifiers based on Python ones. This library features will be included in the C++20 upcoming standard library. Nevertheless, most compilers still does not implement this library.
- The old C's printf is not type-safe and prone to security vulnerabilities if proper care is not taken.
Web Site:
Repository:
C++20 Stadnard library inclusion:
Conan Refence:
See:
- Python String format() - Python Standard Library
- String Formatting with str.format() in Python 3 | DigitalOcean
- Formatting Strings with Python
Library Local Installation for header-only usage
Installation at: ~/dev/include/fmt
$ git clone https://github.com/fmtlib/fmt # Build directory /home/<USER>/dev on Linux $ mkdir -p ~/dev && cd dev # Clone repository $ git clone https://github.com/fmtlib/fmt # Extract headers $ cp -r -v fmt/include ~/dev/ # Delete fmt directory $ rm -rf fmt
Testing code: File - fmttest.cpp
#include <iostream> #include <fstream> #include <cmath> #include <sstream> // If defined before including fmt, uses it as header-only library #define FMT_HEADER_ONLY // Basic functionality #include <fmt/core.h> // fmt string literals "name"_a, "product"_a #include <fmt/format.h> // Print to streams std::cout, std::cerr, std::ostream #include <fmt/ostream.h> #include <fmt/color.h> // #include <fmt/color.h> using namespace fmt::literals; void printHeader(const char* header) { fmt::print("\n{}\n", header); fmt::print("---------------------------------------------\n"); } int main() { printHeader(" ***** EXPERIMENT 1 - Boolean *************"); fmt::print(" true == {0} ; false == {1} \n", true, false); printHeader(" ***** EXPERIMENT 2 - Numeric Base *********"); fmt::print(" [BASES] => dec: {0:d} ; hex = 0x{0:X} " " ; oct = {0:o} ; bin = 0b{0:b} \n", 241 ); printHeader(" ***** EXPERIMENT 3 - Positional arguments ****"); fmt::print(" first = {0}, 2nd = {1}, 1st = {1}, 3rd = {2}\n", 200, "hello", 5.615); printHeader("**** EXPERIMENT 4 - Named Arguments ********* "); fmt::print(" [A] Product => product = {0} id = {1} price = {2}\n" ,"oranges 1 kg", 200, 10.6758 ); // Requires: #include <fmt/format.h> // using namespace fmt::literals; fmt::print(" [B] Product => product = {product} id = {id} price = {price:.2F}\n" , "product"_a = "oranges 1 kg", "id"_a = 200, "price"_a = 10.6758 ); fmt::print(" [B] Product => product = {product} id = {id} price = {price:.2F}\n" , fmt::arg("product", "oranges 1 kg") , fmt::arg("id", 200) , fmt::arg("price", 10.6758 )); printHeader("************ Colored Output ******************"); fmt::print( fmt::fg(fmt::color::aqua) | fmt::emphasis::bold, " [INFO] Voltage Leval = {0:+.3F}\n", 10.6478); fmt::print( fmt::fg(fmt::color::red) | fmt::emphasis::underline, " [ERROR] Fatal Error, shutdown systems code 0x{0:X}\n", 2651); printHeader(" ***** EXPERIMENT 5 - Numeric Formatting ******"); double x = 20.0; fmt::print("The square root of x = {}\n", std::sqrt(x)); x = 28524.0; fmt::print(" log(x) = {:.2F} (2 digit precision)\n", std::log(x)); fmt::print(" log(x) = {:+.6F} (6 digit precision)\n", std::log(x)); fmt::print(" 2000 * log(x) = {:+.6G} (6 digit precision)\n", 1e5 * std::log(x)); fmt::print(" log(x) = {0:+.8E} ; sqrt(x) = {1:+8E} (8 digit precision)\n", std::log(x), std::sqrt(x)); printHeader(" ***** EXPERIMENT 6 - Print numeric table ******"); int i = 0; for(double x = 0.0; x <= 4.0; x += 0.5) fmt::print("{0:8d}{1:10.5F}{2:10.5F}\n", i++, x, std::exp(x)); printHeader(" ***** EXPERIMENT 7 - Print table to file *******"); // std::ofstream file("/tmp/table.txt"); std::stringstream file; // Fake file i = 0; // Note: Requires <fmt/ostream.h> for(double x = -4.0; x <= 4.0; x += 1.0) fmt::print(file, "{0:8d}{1:10.5F}{2:10.5F}\n", i++, x, std::exp(x)); fmt::print("File content = \n{0}", file.str()); return 0; }
Program output:
***** EXPERIMENT 1 - Boolean *************
---------------------------------------------
true == true ; false == false
***** EXPERIMENT 2 - Numeric Base *********
---------------------------------------------
[BASES] => dec: 241 ; hex = 0xF1 ; oct = 361 ; bin = 0b11110001
***** EXPERIMENT 3 - Positional arguments ****
---------------------------------------------
first = 200, 2nd = hello, 1st = hello, 3rd = 5.615
**** EXPERIMENT 4 - Named Arguments *********
---------------------------------------------
[A] Product => product = oranges 1 kg id = 200 price = 10.6758
[B] Product => product = oranges 1 kg id = 200 price = 10.68
[B] Product => product = oranges 1 kg id = 200 price = 10.68
************ Colored Output ******************
---------------------------------------------
[1m[38;2;000;255;255m [INFO] Voltage Leval = +10.648
[0m[4m[38;2;255;000;000m [ERROR] Fatal Error, shutdown systems code 0xA5B
[0m
***** EXPERIMENT 5 - Numeric Formatting ******
---------------------------------------------
The square root of x = 4.47213595499958
log(x) = 10.26 (2 digit precision)
log(x) = +10.258501 (6 digit precision)
2000 * log(x) = +1.02585e+06 (6 digit precision)
log(x) = +1.02585011E+01 ; sqrt(x) = +1.688905E+02 (8 digit precision)
***** EXPERIMENT 6 - Print numeric table ******
---------------------------------------------
0 0.00000 1.00000
1 0.50000 1.64872
2 1.00000 2.71828
3 1.50000 4.48169
4 2.00000 7.38906
5 2.50000 12.18249
6 3.00000 20.08554
7 3.50000 33.11545
8 4.00000 54.59815
***** EXPERIMENT 7 - Print table to file *******
---------------------------------------------
File content =
0 -4.00000 0.01832
1 -3.00000 0.04979
2 -2.00000 0.13534
3 -1.00000 0.36788
4 0.00000 1.00000
5 1.00000 2.71828
6 2.00000 7.38906
7 3.00000 20.08554
8 4.00000 54.59815
Compilation:
$ g++ fmttest.cpp -o app.bin -std=c++1z -Wall -I$HOME/dev/include # Or, on Linux $ clang++ fmttest.cpp -o app.bin -std=c++1z -Wall -I/home/<USER>/dev/include # Or, On OSX $ clang++ fmttest.cpp -o app.bin -std=c++1z -Wall -I/Users/<USER>/dev/include
The code can be compiled without specifying the include path, by adding the following code to the file ~/.profile on Linux.
#------------ Local Libraries Installation --------------------- LOCAL_LIB_PATH=~/dev export CPLUS_INCLUDE_PATH=$LOCAL_LIB_PATH/include:$CPLUS_INCLUDE_PATH export C_INCLUDE_PATH=$LOCAL_LIB_PATH/include:$C_INCLUDE_PATH export LIBRARY_PATH=$LOCAL_LIB_PATH/lib:$LIBRARY_PATH export LD_LIBRARY_PATH=$LOCAL_LIB_PATH/lib:$LD_LIBRARY_PATH
After this configuration was set, the code can be compiled with:
$ g++ fmttest.cpp -o app.bin -std=c++1z -Wall # Header only compilation takes 2 seconds $ time g++ fmttest.cpp -o app.bin -std=c++1z -Wall real 0m1.824s user 0m1.650s sys 0m0.156s
Once the environment variabble CPLUS_INCLUDE_PATH is set, the library can be loaded from CERN's Root or Cling REPL with:
#define FMT_HEADER_ONLY #include <fmt/format.h> #include <fmt/color.h> #include <fmt/ostream.h> >> fmt::print(" x = {0:.5F}, sqrt(x) = {1:+.8F}\n", 20.6, std::sqrt(20.6)) x = 20.60000, sqrt(x) = +4.53872229 >> // Print with color foreground blue >> fmt::print(fmt::fg(fmt::color::blue), " [INFO] x = {0:.5E}\n", 20.6) [INFO] x = 2.06000E+01 // Print with background color blue >> fmt::print(fmt::bg(fmt::color::blue), " [INFO] x = {0:.5E}\n", 20.6) [INFO] x = 2.06000E+01 >>
1.4.2 tinyprintf
Single-file header-only library replacement for printf. The advatange of this library is the extensibility, easy-of-use and deployment as it just a single header-file.
Repository:
Sample Project:
File: CMakeLists.txt
cmake_minimum_required(VERSION 2.8) project(tinyprintf-test) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) #============= Functions and macros ===========================# macro(Download_Single_Headerlib FILE URL) file(DOWNLOAD ${URL} ${CMAKE_BINARY_DIR}/include/${FILE}) IF(NOT Download_Single_Headerlib_flag) include_directories(${CMAKE_BINARY_DIR}/include) set(Download_Single_Headerlib_flag TRUE) ENDIF() endmacro() Download_Single_Headerlib( tinyformat.h "https://raw.githubusercontent.com/c42f/tinyformat/master/tinyformat.h" ) #============ Target settings ==================================# add_executable(main main.cpp)
File: main.cpp
#include <iostream> #include <string> #include <cmath> #include <vector> #include <tinyformat.h> template<typename T> void display(T&& x) { tfm::printfln(" Function = %s ; Value x = %s", __FUNCTION__, x); } struct Point3D { double x, y, z; }; /** Enables printing user defined data with tinyprintf library */ std::ostream& operator<<(std::ostream& os, Point3D const& point ) { auto [x, y, z] = point; return os << " Point3d{ x = " << x << " ; y = " << y << " ; z = " << z << " } "; } int main(int argc, char** argv) { std::string s = "Hello world"; tfm::printf(" LINE 1 => s = %s n1 = %d f = %.3f \n", s, 10, 283.41345); tfm::printfln(" LINE 2 => arg1 = %1$s ; arg3 = %3$s ; arg2 = %2$d ", "A1", 1003, "A3"); // Templated function display(10); display("Hello world C++20 ... modules"); // Print user-defined type tfm::printfln("\n User Defined Data =>> = %s", Point3D{3.5, 100.34, -90.341}); //==== Print to stream ===========// std::stringstream ss; for(int i = 0; i < 5; i++) { tfm::format(ss, "%8.d %10.5f\n", i, std::exp(i)); } tfm::printfln("\nFunction tabulation result => \n %s", ss.str()); return 0; }
Output of executable main:
% ./main
LINE 1 => s = Hello world n1 = 10 f = 283.413
LINE 2 => arg1 = A1 ; arg3 = A3 ; arg2 = 1003
Function = display ; Value x = 10
Function = display ; Value x = Hello world C++20 ... modules
User Defined Data =>> = Point3d{ x = 3.5 ; y = 100.34 ; z = -90.341 }
Function tabulation result =>
0 1.00000
1 2.71828
2 7.38906
3 20.08554
4 54.59815
1.5 Pretty Printing
1.5.1 cxx-prettyprint - STL container pretty print
Description:
- "A header-only library for C++(0x) that allows automagic pretty-printing of any container."
- Note: as this library is single-file and header-only, it does not need any pre-compilation. All that is needed for using it is to download the file prettyprint.hpp and add it to the project directory or any other include directory.
Website:
Repository:
Examples in CERN-Root REPL
Step 1: Download the library and start the CERN's ROOT Repl (Cling).
$ curl -O -L https://raw.githubusercontent.com/louisdx/cxx-prettyprint/master/prettyprint.hpp $ ~/opt/root/bin/root.exe ------------------------------------------------------------ | Welcome to ROOT 6.14/04 http://root.cern.ch | | (c) 1995-2018, The ROOT Team | | Built for linuxx8664gcc | | From tags/v6-14-04@v6-14-04, Aug 23 2018, 17:00:44 | | Try '.help', '.demo', '.license', '.credits', '.quit'/'.q' | ------------------------------------------------------------
Include header in the repl:
>> #include "prettyprint.hpp""
Print vector:
>> auto xs = std::vector<double>{434.4, -10.54, 9.654, 45.23, -10.56}; //------- Print Vector -----------------// >> >> std::cout << " xs = " << xs << std::endl; xs = [5](434.4 -10.54 9.654 45.23 -10.56 ) >>
Print tuple:
>> auto t = std::make_tuple(std::string("hello"), 100) (std::tuple<basic_string<char>, int> &) { "hello", 100 } >> std::cout << " t = " << t << std::endl; t = (hello, 100) >> auto tt = std::make_tuple(std::string("hello"), 100, 'x') (std::tuple<basic_string<char>, int, char> &) { "hello", 100, 'x' } >> >> std::cout << " tt = " << tt << std::endl; tt = (hello, 100, x)
Print map:
>> std::map<std::string, double> dataset {{"USD", 200.3}, {"BRL", 451.34}, {"CAD", 400.5}, {"AUD", 34.65}}; >> std::cout << " dataset = " << dataset << std::endl; dataset = [(AUD, 34.65), (BRL, 451.34), (CAD, 400.5), (USD, 200.3)] >>
1.5.2 pprint - Pretty print library for C++17
PPrint is an easy and simple to use header-only pretty printing library for C++17 capable of printing all C++17 containers, including variants and optional in a nice way.
Repository:
Download the library:
$ cd <PROJECT> $ curl -O -L https://raw.githubusercontent.com/p-ranav/pprint/v0.9.1/include/pprint.hpp
File: main.cpp
#include <iostream> #include <string> #include <vector> #include <map> #include <complex> // Library from: https://github.com/p-ranav/pprint/tree/v0.9.1 #include <include/pprint.hpp> using cpl = std::complex<double>; int main() { auto printer = pprint::PrettyPrinter{}; std::puts("\n========= Print Numbers ============"); printer.print(100); printer.print(59.15); std::puts("\n======= Print string with/without quotes ====="); printer.print(" Testing CEE PLUS PLUS Printer"); printer.quotes(false); printer.print(" Testing CEE PLUS PLUS Printer"); printer.quotes(true); std::puts("\n=========== Print booleans ==========="); printer.print(true); printer.print(false); std::puts("\n========== Print Null Pointer ========="); printer.print(nullptr); std::puts("\n======== Print complex numbers ========="); cpl x1{10.0, 15}; auto x2 = cpl{-36.34, 98.765}; cpl x3 = {-2.5312, -9.81}; printer.quotes(false); printer.print("x1 = ", x1, " ; x2 = ", x2, " ; x3 = ", x3); std::puts("\n======= STL Container ================="); std::puts(" --->> Print a vector <<----- "); std::vector<std::string> words = { "c++", "Ada", "Scala", "C++17", "Serial" }; printer.print(words); std::puts(" --->> Print a map <<--------"); std::map<std::string, double> dataset = { {"x", -9.4351}, {"mx", -100.35}, {"g", 9.814} }; printer.print(dataset); std::puts(" --->> Print a map / Compact <<--------"); printer.compact(true); printer.print(dataset); std::puts(" -->> Print a vector of tuples <<------"); printer.compact(false); auto xlist = std::vector<std::tuple<std::string, int>>{ {"CAD", 100}, {"AUD", 900 }, {"BRL", 871}, {"EUR", 9871} }; printer.print(xlist); std::puts("\n=== Print C++17 Variants ================="); using var = std::variant<int, std::string, std::vector<int>>; std::vector<var> varlist = { 100, "hello", 51, std::vector{23, 100, -9, 8, 100}, "world" }; printer.print(varlist); return 0; }
Output:
./main.bin
========= Print Numbers ============
100
59.15
======= Print string with/without quotes =====
" Testing CEE PLUS PLUS Printer"
Testing CEE PLUS PLUS Printer
=========== Print booleans ===========
true
false
========== Print Null Pointer =========
nullptr
======== Print complex numbers =========
x1 = (10 + 15i) ; x2 = (-36.34 + 98.765i) ; x3 = (-2.5312 + -9.81i)
======= STL Container =================
--->> Print a vector <<-----
[
c++,
Ada,
Scala,
C++17,
Serial
]
--->> Print a map <<--------
{
g : 9.814,
mx : -100.35,
x : -9.4351
}
--->> Print a map / Compact <<--------
{g : 9.814, mx : -100.35, x : -9.4351}
-->> Print a vector of tuples <<------
[
("CAD", 100),
("AUD", 900),
("BRL", 871),
("EUR", 9871)
]
=== Print C++17 Variants =================
[
100,
hello,
51,
[23, 100, -9, 8, 100],
world
]
1.6 Command Line Parsing
1.6.1 CLI11 Library
CLI11 is a small and lightweight header-only library for command line parsing.
Repository:
Documentation:
Doxygen API docs:
Conan reference:
Sample Project:
File: CMakeLists.txt
cmake_minimum_required(VERSION 2.8) project(cli11-app) #========================================# set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) #=========== Conan Bootstrap =================# # Download automatically, you can also just copy the conan.cmake file if(NOT EXISTS "${CMAKE_BINARY_DIR}/conan.cmake") message(STATUS "Downloading conan.cmake from https://github.com/conan-io/cmake-conan") file(DOWNLOAD "https://github.com/conan-io/cmake-conan/raw/v0.13/conan.cmake" "${CMAKE_BINARY_DIR}/conan.cmake") endif() include(${CMAKE_BINARY_DIR}/conan.cmake) set(CONAN_PROFILE default) conan_cmake_run( REQUIRES CLI11/1.8.0@cliutils/stable BASIC_SETUP BUILD missing ) #=========== Find Package ================# find_package(CLI11 REQUIRED) #=========== Targets ======================# # Note: CLI11 is a header-only library and does not need Linking add_executable(httpserver main.cpp)
File: main.cpp
#include <iostream> #include <fstream> #include <string> #include <CLI/CLI.hpp> int main(int argc, char** argv) { CLI::App app{ "C++ http Web Server"}; app.footer("\n Creator: Somebody else."); // Sets the current path that will be served by the http server std::string dir = "default"; app.add_option("directory", dir, "Directory served")->required(); // Sets the port that the server will listen to int port = 8080; app.add_option("-p,--port", port, "TCP port which the server will bind/listen to"); // Set the the hostname that the server will listen to // Default: 0.0.0.0 => Listen all hosts std::string host = "0.0.0.0"; app.add_option("--host", host, "Host name that the sever will listen to."); app.validate_positionals(); CLI11_PARSE(app, argc, argv); std::cout << "Running server at port = " << port << "\n and listen to host = " << host << "\n serving directory = " << dir << "\n"; return 0; }
Sample program output:
- Display help:
$ ./httpserver -h C++ http Web Server Usage: ./httpserver [OPTIONS] directory Positionals: directory TEXT REQUIRED Directory served Options: -h,--help Print this help message and exit -p,--port INT TCP port which the server will bind/listen to --host TEXT Host name that the sever will listen to. Creator: Somebody else.
- Run app.
$ ./httpserver directory is required Run with --help for more information. $ ./httpserver /var/data/www Running server at port = 8080 and listen to host = 0.0.0.0 servind directory = /var/data/www $ ./httpserver /var/data/www --port=9090 Running server at port = 9090 and listen to host = 0.0.0.0 serving directory = /var/data/www $ ./httpserver --port=9090 --host=localhost /home/user/pages Running server at port = 9090 and listen to host = localhost serving directory = /home/user/pages
1.6.2 Clipp library
Single-file header-only library for parsing command line arguments (command line option parsing). It supports: positional values (required arguments); optional values; manpage generation and so on.
- Repository: https://github.com/muellan/clipp
Sample Project
File: CMakeLists.txt
cmake_minimum_required(VERSION 3.0) project(clipp-test) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) #============= Functions and macros ===========================# macro(Download_Single_Headerlib FILE URL) file(DOWNLOAD ${URL} ${CMAKE_BINARY_DIR}/include/${FILE}) IF(NOT Download_Single_Headerlib_flag) include_directories(${CMAKE_BINARY_DIR}/include) set(Download_Single_Headerlib_flag TRUE) ENDIF() endmacro() Download_Single_Headerlib( clipp.h https://raw.githubusercontent.com/muellan/clipp/v1.2.3/include/clipp.h ) #============ Targets settings ==================================# add_executable( application application.cpp )
File: application.cpp
#include <iostream> #include <string> #include <clipp.h> struct ServerOptions { // --------- Required values -------------------// int port; std::string host; // -------- Optional values -------------------// int loglevel = 1; std::string name = "untitled"; bool require_authentication = false; bool verbose = false; }; int main(int argc, char* argv []) { ServerOptions opts; auto cli = ( // --- Positional values ===>> Required --------------// clipp::value("host name", opts.host) , clipp::value("server port", opts.port) // --- Optional values ------------------------// , clipp::option("-v", "--verbose") .set(opts.verbose) .doc("Enable versbosity") , clipp::option("-a", "--require-auth") .set(opts.require_authentication) .doc("Require authentication") , clipp::option("--loglevel") & clipp::value("set server's log level", opts.loglevel) , clipp::option("-n", "--name") & clipp::value("server name", opts.name) ); if( !clipp::parse(argc, argv, cli) ) { std::cout << clipp::make_man_page(cli, argv[0] ); return EXIT_SUCCESS; } std::cout << std::boolalpha; std::cout << " Running server " << " \n port = " << opts.port << " \n host = " << opts.host << " \n verbose = " << opts.verbose << " \n require_auth = " << opts.require_authentication << " \n name = " << opts.name << " \n log level = " << opts.loglevel << "\n"; return EXIT_SUCCESS; }
Running
Building:
$ cmake -H. -B_build -DCMAKE_BUILD_TYPE=Debug $ cmake --build _build --target
Running [1]:
$ ./application
SYNOPSIS
./application <host name> <server port> [-v] [-a] [--loglevel <set server's log level>] [-n
<server name>]
OPTIONS
-v, --verbose
Enable versbosity
-a, --require-auth
Require authentication
Running [2]:
$ ./application 127.0.0.1 8080
Running server
port = 8080
host = 127.0.0.1
verbose = false
require_auth = false
name = untitled
log level = 1
Running [3]:
$ ./application 127.0.0.1 8080 --verbose --name "lisp server"
Running server
port = 8080
host = 127.0.0.1
verbose = true
require_auth = false
name = lisp server
log level = 1
1.7 Serialization
1.7.1 Cereal - Serialization library
Cereal is a lightweight header-only library for serialization which supports a wide variety of serialization formats such as binary, XML and JSON. The library also provides lots of facilities for serializing and deserializing STL containers.
- License: BSD
- Documentation and official web site:
- Github Repository:
- Conan Reference:
Serialization Challenges
Despite what it may look like, serialization is not easy, there are lots of serialization pitfalls that a library shoudl deal with:
- Machine endianess:
- The order that bytes of numeric data are loaded into memory depends on the machine architecture, therefore a numeric data stored in a binary file generated in a machine with a little endian processor, may be read in a wrong way by a big endian machine. So, in order to be portable, a binary file must use a default endianess independent of the any processor.
- Data Sizes:
- C and C++ binary sizes of fundamental data types such as int, long and long long are not constant across different operating systems and machine architectures. So a value of long type save in binary format in one machine may be read in a wrong way in a machine where the long type has a different size in bytes. The only way to ensure that the data type is portable and avoid bad surprises is to use fixed width integers from header <stdint> uint32_t, uint64_t and so on.
- Data Versioning
- In order to avoid data corruption, a serialization format should support multiple versions of the data structure being serialized and check the version of the data whenever it is deserialized from any stream.
Supported Serialization Formats:
- XML
- JSON
- Binary
Headers:
- Serialization formats:
- Binary Format:
- <cereal/archives/binary.hpp>
- Portable Binary Format:
- <cereal/archives/portable_binary.hpp>
- XML
- <cereal/archives/xml.hpp>
- JSON - JavaScript Object Notation
- <cereal/archives/json.hpp>
- Binary Format:
- Support for serializing STL containers
- <cereal/types/vector.hpp> => STL Vector std::vector serialization
- Support for polymorphic types serialization
- <cereal/types/polymorphic.hpp>
Sample Code:
- File: cereal_test.cpp
#include <iostream> #include <iomanip> #include <string> #include <vector> #include <fstream> // std::ofstream #include <sstream> // std::stringstream #include <cereal/archives/binary.hpp> // #include <cereal/archives/portable_binary.hpp> #include <cereal/archives/xml.hpp> #include <cereal/archives/json.hpp> // Allows std::vector serialization #include <cereal/types/vector.hpp> struct DummyClass { double x; float y; size_t N; std::vector<int> list; DummyClass(): x(0), y(0), N(0){ } DummyClass(double x, float y, size_t N) : x(x), y(y), N(N){ } void Add(int x) { list.push_back(x); } template<typename Archive> void serialize(Archive& archive) { // Archive without name-value pair //-------------------------------- // archive(x, y, N, list); // Archive with name-value pair //------------------------------- archive(cereal::make_nvp("x", x), cereal::make_nvp("y", y), cereal::make_nvp("N", N), cereal::make_nvp("list", list) ); } void show(std::ostream& os) { os << "DummyClass { x = " << x << " ; y = " << y << " ; N = " << N << " } => "; os << " List[ "; for(auto const& e: list) os << " " << e; os << " ] " << "\n"; } }; int main() { // ============ Binary Serialization ==================// // Memory "file" simulating a disk file auto mock_file = std::stringstream{}; std::cout << "\n=== Experiment 1 - Serialize object to binary file ===\n"; { auto outArchive = cereal::BinaryOutputArchive(mock_file); DummyClass obj{100.6534, 45.5f, 100}; obj.Add(100); obj.Add(200); obj.Add(50); obj.Add(80); outArchive(obj); std::cout << " Content of mock-file = " << mock_file.str() << std::endl; } std::cout << "\n=== Experiment 2 - Deserialize object from binary file ====\n" ; { auto inArchive = cereal::BinaryInputArchive(mock_file); DummyClass cls; inArchive(cls); cls.show(std::cout); } //============= XML Serialization ============================// // auto xmlFile = std::ofstream("/tmp/dataset.xml"); auto xmlFile = std::stringstream{}; std::cout << "\n=== Experiment 3 - Serialize object to XML file ====\n" ; { auto outArchive = cereal::XMLOutputArchive(xmlFile); DummyClass obj1{200.0, -802.5f, 900}; obj1.Add(100); obj1.Add(200); obj1.Add(50); obj1.Add(80); DummyClass obj2{400.0, -641.f, 300}; outArchive(obj1, obj2); } // Note: Cereal uses RAII to flush the archive output, so the output is only // guaranteeed to be written to the stream when the archive go out of escope. std::cout << " [TRACE] xmlFile = " << xmlFile.str() << std::endl; std::cout << "\n=== Experiment 4 - Deserialize object from XML file ===\n" ; { auto inArchive = cereal::XMLInputArchive(xmlFile); DummyClass obj1, obj2; // Read two objects from stream inArchive(obj1, obj2); obj1.show(std::cout); obj2.show(std::cout); } // ============= JSON Serialization =================================// // auto xmlFile = std::ofstream("/tmp/dataset.xml"); auto jsonFile = std::stringstream{}; std::cout << "\n=== Experiment 5 - Serialize object to JSON file ====\n" ; { auto outArchive = cereal::JSONOutputArchive(jsonFile); DummyClass obj1{200.0, -802.5f, 900}; obj1.Add(100); obj1.Add(200); obj1.Add(50); obj1.Add(80); DummyClass obj2{400.0, -641.f, 300}; outArchive(cereal::make_nvp("object1", obj1), cereal::make_nvp("object2", obj2)); } std::cout << " [TRACE] JSON File =\n" << jsonFile.str() << std::endl; std::cout << "\n=== Experiment 6 - Deserialize object from JSON file ====\n" ; { auto inArchive = cereal::JSONInputArchive(jsonFile); DummyClass obj1, obj2; // Read two objects from stream inArchive(obj1, obj2); obj1.show(std::cout); obj2.show(std::cout); } return 0; }
Program output:
$ ./cereal_test.bin
=== Experiment 1 - Serialize object to binary file ===
Content of mock-file = 6�;N�)Y@��6Bd��������������d�������2���P���
=== Experiment 2 - Deserialize object from binary file ====
DummyClass { x = 100.653 ; y = 45.5 ; N = 100 } => List[ 100 200 50 80 ]
=== Experiment 3 - Serialize object to XML file ====
[TRACE] xmlFile = <?xml version="1.0" encoding="utf-8"?>
<cereal>
<value0>
<x>200</x>
<y>-802.5</y>
<N>900</N>
<list size="dynamic">
<value0>100</value0>
<value1>200</value1>
<value2>50</value2>
<value3>80</value3>
</list>
</value0>
<value1>
<x>400</x>
<y>-641</y>
<N>300</N>
<list size="dynamic"/>
</value1>
</cereal>
=== Experiment 4 - Deserialize object from XML file ===
DummyClass { x = 200 ; y = -802.5 ; N = 900 } => List[ 100 200 50 80 ]
DummyClass { x = 400 ; y = -641 ; N = 300 } => List[ ]
=== Experiment 5 - Serialize object to JSON file ====
[TRACE] JSON File =
{
"object1": {
"x": 200.0,
"y": -802.5,
"N": 900,
"list": [
100,
200,
50,
80
]
},
"object2": {
"x": 400.0,
"y": -641.0,
"N": 300,
"list": []
}
}
=== Experiment 6 - Deserialize object from JSON file ====
DummyClass { x = 200 ; y = -802.5 ; N = 900 } => List[ 100 200 50 80 ]
DummyClass { x = 400 ; y = -641 ; N = 300 } => List[ ]
1.7.2 YAS - Yet Another Serialization Library
YAS - Yet Another Serialization Library - High performance ligthweight header-only serialization library with support for all STL containers.
Repository:
More Examples:
Supported Serialization Formats:
- binary (portable, endianess-independent)
- text
- json (not fully compatible)
Problems:
- Less documentation
- Lack of doxygen comments
- Not comptabile with C++'s standard library streams such as std::ostream, std::fstream, std::cout.
CMake Project Example
- File: CMakeLists.txt
cmake_minimum_required(VERSION 3.9) project(YAS_PROJECT) #========== Global Configurations =============# #----------------------------------------------# set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) set(CMAKE_CXX_EXTENSIONS OFF) #------------- Fetch Serialization Library YAS -------------------# include( FetchContent ) FetchContent_Declare( yas GIT_REPOSITORY "https://github.com/niXman/yas.git" GIT_TAG "7.0.4" ) FetchContent_MakeAvailable(yas) include_directories("${yas_SOURCE_DIR}/include/" ) #========== Targets Configurations ============# add_executable(executable serialize.cpp)
- File: serialize.cpp
#include <iostream> #include <deque> #include <algorithm> #include <numeric> #include <initializer_list> #include <fstream> #include <yas/serialize.hpp> #include <yas/std_types.hpp> #include <yas/text_iarchive.hpp> #include <yas/text_oarchive.hpp> /** @brief Read whole input stream to a string and returns it * Requires headers: <iostream> and <sstream> */ std::string istreamToString(std::istream& is){ if(is.bad()){ throw std::runtime_error("Error: stream has errors."); } std::stringstream ss; ss << is.rdbuf(); return ss.str(); } class Stats { std::string m_name = ""; std::deque<double> m_data = {}; public: Stats() { } Stats(std::initializer_list<double> const& list) : m_data(list.begin(), list.end()) { } void insert(double x){ m_data.push_back(x); } double get(size_t index) const { return m_data[index]; } size_t size() const { return m_data.size(); } auto begin() { return m_data.begin(); } auto end() { return m_data.end(); } std::string name() const { return m_name; } void set_name(std::string name) { m_name = name; } double mean() const { double total = std::accumulate(m_data.begin(), m_data.end(), 0.0); return total / m_data.size(); } double first() const { return m_data.front(); } double last() const{ return m_data.back(); } /** Required friend function for making class printable */ friend std::ostream& operator<<(std::ostream& os, const Stats& stat) { os << "Stats { name = '" << stat.m_name << "' ; data = [ "; for(auto x: stat.m_data) { os << x << ", "; } return os << " ] }"; } /** Required method for making the class serializable */ template<typename Archive> void serialize(Archive& ar) { // NVP => Name-value-pair ar & YAS_OBJECT_NVP( "Stats" ,("name", m_name) ,("data", m_data) ); } }; int main() { const char* jsonfile = "program_data.json"; std::cout << "\n ==== EXPERIMENT 1 ====== Save data to file ========\n\n"; { auto stats = Stats{4.5, -10.3, 58.66, 10.6, 9.615, 56.156, 90.51, -62.0}; stats.set_name("Price change"); // std::cout << " => Name " << stats.name() << std::endl; std::cout << " => stats = " << stats << std::endl; std::cout << " => mean = " << stats.mean() << std::endl; // Remove file if it exists std::remove(jsonfile); // Save archive data in a JSON file yas::save<yas::file | yas::json>(jsonfile, stats); } // Check file content auto ifs = std::ifstream{jsonfile}; auto content = istreamToString(ifs); std::cout << "\n File content = \n " << content << std::endl; std::cout << "\n ==== EXPERIMENT 2 ====== Load data from file ======\n\n"; { auto statsB = Stats{}; yas::load<yas::file | yas::json>(jsonfile, statsB); std::cout << " => stats = " << statsB << std::endl; std::cout << " => mean = " << statsB.mean() << std::endl; } std::cout << "\n ==== EXPERIMENT 3 ====== Load/Save data from memory ======\n\n"; // Save to memory yas::mem_ostream os; auto statsX = Stats{14.5, 25.16, 18.66, -10.6, 62.615, +46.1566, 90.51, 62.61}; statsX.set_name("Oil prices"); { auto archive = yas::binary_oarchive<yas::mem_ostream>(os); archive(statsX); std::cout << " StatsX = " << statsX << std::endl; std::cout << " [TRACE] Saved to memory OK." << std::endl; } { auto is = yas::mem_istream(os.get_intrusive_buffer()); auto archive = yas::binary_iarchive<yas::mem_istream>(is); auto statsY = Stats(); archive(statsY); std::cout << " [TRACE] Load from memory OK." << std::endl; std::cout << " StatsY = " << statsY << std::endl; } return 0; }
- Program output:
==== EXPERIMENT 1 ====== Save data to file ========
=> stats = Stats { name = 'Price change' ; data = [ 4.5, -10.3, 58.66, 10.6, 9.615, 56.156, 90.51, -62, ] }
=> mean = 19.7176
File content =
{"name":"Price change","data":[4.5,-10.3,58.66,10.6,9.615,56.156,90.51,-62.0]}
==== EXPERIMENT 2 ====== Load data from file ======
=> stats = Stats { name = 'Price change' ; data = [ 4.5, -10.3, 58.66, 10.6, 9.615, 56.156, 90.51, -62, ] }
=> mean = 19.7176
==== EXPERIMENT 3 ====== Load/Save data from memory ======
StatsX = Stats { name = 'Oil prices' ; data = [ 14.5, 25.16, 18.66, -10.6, 62.615, 46.1566, 90.51, 62.61, ] }
[TRACE] Saved to memory OK.
[TRACE] Load from memory OK.
StatsY = Stats { name = 'Oil prices' ; data = [ 14.5, 25.16, 18.66, -10.6, 62.615, 46.1566, 90.51, 62.61, ] }
1.8 Parsers
1.8.1 TinyXML2 - Lightweight XML parser
Simple and ligtweight C++ library for parsing XML files.
Site:
Repository:
Conan Reference:
Conan package repository:
Example:
Full Project Code:
File: tinyxml2-test.cpp
- This file parses the XML taken from eurofxref-daily.xml which contains a set of FX exchange rates.
#include <iostream> #include <iomanip> #include <tinyxml2.h> #define ENABLE_ASSERT #ifdef ENABLE_ASSERT #define M_ASSERT(expr) \ { \ if(!(expr)){ \ std::cerr << "ASSERTION FAILURE: \n"; \ std::cerr << " => Condition: " << #expr << "\n"; \ std::cerr << " => Function: " << __FUNCTION__ << "\n"; \ std::cerr << __FILE__ << ":" << __LINE__ << ":" << "\n"; \ std::terminate(); \ } \ } #else #define M_ASSERT(expr) #endif using tinyxml2::XMLText; using tinyxml2::XMLElement; using tinyxml2::XMLNode; extern const char* exchangeRatesXML; int main() { std::cout << " [INFO] Running TinyXMl2 " << std::endl; tinyxml2::XMLDocument doc; if(doc.Parse( exchangeRatesXML) != tinyxml2::XML_SUCCESS) { std::cout << " [ERROR] Failed to parse XML" << std::endl; return EXIT_FAILURE; } std::cout << " [OK] XML parsed successfully" << std::endl; tinyxml2::XMLPrinter printer; doc.Print(&printer); std::cout << "Value: doc.FirstChild()->Value() = " << doc.FirstChild()->Value() << std::endl; XMLElement* elem = doc.FirstChildElement("gesmes:Envelope"); M_ASSERT(elem != nullptr); if(elem){ std::cout << " Element found. OK " << std::endl; std::cout << " =>> Element Name = " << elem->Name() << std::endl; } XMLElement* elem1 = elem->FirstChildElement("Cube"); M_ASSERT(elem1 != nullptr); std::cout << " =>> Found Node Name: " << elem1->ToElement()->Name() << "\n"; XMLElement* elem2 = elem1->FirstChildElement("Cube"); M_ASSERT(elem2 != nullptr); const char* time = elem2->Attribute("time"); M_ASSERT(time != nullptr); // XML node with: <Cube time = 'xxxx-xx-xx'> std::cout << " => Time = " << time << "\n\n"; std::cout << std::fixed << std::setprecision(3); std::cout << " ===== Exchange rates per Euro ====" << std::endl; for(XMLElement* e = elem2->FirstChildElement("Cube") ; e != nullptr; e = e->NextSiblingElement("Cube") ) { std::cout << std::setw(10) << e->Attribute("currency") << std::setw(15) << std::stod(e->Attribute("rate")) << std::endl; } return doc.ErrorID(); } // Source: https://www.ecb.europa.eu/stats/eurofxref/eurofxref-daily.xml const char* exchangeRatesXML = R"( <?xml version="1.0" encoding="UTF-8"?> <gesmes:Envelope xmlns:gesmes="http://www.gesmes.org/xml/2002-08-01" xmlns="http://www.ecb.int/vocabulary/2002-08-01/eurofxref"> <gesmes:subject>Reference rates</gesmes:subject> <gesmes:Sender> <gesmes:name>European Central Bank</gesmes:name> </gesmes:Sender> <Cube> <Cube time='2019-06-14'> <Cube currency='USD' rate='1.1265'/> <Cube currency='JPY' rate='121.90'/> <Cube currency='BGN' rate='1.9558'/> <Cube currency='CZK' rate='25.540'/> <Cube currency='DKK' rate='7.4676'/> <Cube currency='GBP' rate='0.89093'/> <Cube currency='HUF' rate='321.53'/> <Cube currency='PLN' rate='4.2534'/> <Cube currency='RON' rate='4.7233'/> <Cube currency='SEK' rate='10.6390'/> <Cube currency='CHF' rate='1.1211'/> <Cube currency='ISK' rate='141.50'/> <Cube currency='NOK' rate='9.7728'/> <Cube currency='HRK' rate='7.4105'/> <Cube currency='RUB' rate='72.3880'/> <Cube currency='TRY' rate='6.6427'/> <Cube currency='AUD' rate='1.6324'/> <Cube currency='BRL' rate='4.3423'/> <Cube currency='CAD' rate='1.5018'/> <Cube currency='CNY' rate='7.7997'/> <Cube currency='HKD' rate='8.8170'/> <Cube currency='IDR' rate='16128.10'/> <Cube currency='ILS' rate='4.0518'/> <Cube currency='INR' rate='78.6080'/> <Cube currency='KRW' rate='1333.60'/> <Cube currency='MXN' rate='21.6073'/> <Cube currency='MYR' rate='4.6981'/> <Cube currency='NZD' rate='1.7241'/> <Cube currency='PHP' rate='58.539'/> <Cube currency='SGD' rate='1.5403'/> <Cube currency='THB' rate='35.101'/> <Cube currency='ZAR' rate='16.6529'/> </Cube> </Cube> </gesmes:Envelope> )";
File: CMakeLists.txt
cmake_minimum_required(VERSION 3.9) project(tinyxml2-test) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) #=========== Conan Bootstrap =================# # Download automatically, you can also just copy the conan.cmake file if(NOT EXISTS "${CMAKE_BINARY_DIR}/conan.cmake") message(STATUS "Downloading conan.cmake from https://github.com/conan-io/cmake-conan") file(DOWNLOAD "https://github.com/conan-io/cmake-conan/raw/v0.13/conan.cmake" "${CMAKE_BINARY_DIR}/conan.cmake") endif() include(${CMAKE_BINARY_DIR}/conan.cmake) set(CONAN_PROFILE default) conan_cmake_run( REQUIRES tinyxml2/7.0.1@nicolastagliani/stable BASIC_SETUP BUILD missing ) #=========== Find Package ================# include(tinyxml2_helper.cmake) #=========== Targets =====================# add_executable(tinyxml2-test tinyxml2-test.cpp) target_link_libraries(tinyxml2-test PRIVATE ${tinyxml2_LIBRARY})
File: tinyxml2_helper.cmake
# Credits: https://github.com/nicolastagliani/conan-tinyxml2/issues/3 include( FindPackageHandleStandardArgs ) find_path( tinyxml2_INCLUDE_DIR NAMES tinyxml2.h PATHS ${CONAN_INCLUDE_DIRS_TINYXML2} ) find_library( tinyxml2_LIBRARY NAMES ${CONAN_LIBS_TINYXML2} PATHS ${CONAN_LIB_DIRS_TINYXML2} ) find_package_handle_standard_args( tinyxml2 DEFAULT_MSG tinyxml2_INCLUDE_DIR ) if( tinyxml2_FOUND ) set( tinyxml2_INCLUDE_DIRS ${tinyxml2_INCLUDE_DIR} ) set( tinyxml2_LIBRARIES ${tinyxml2_LIBRARY} ) get_filename_component( tinyxml2_CONFIG_PATH ${CONAN_TINYXML2_ROOT} DIRECTORY ) get_filename_component( tinyxml2_HASH ${CONAN_TINYXML2_ROOT} NAME ) get_filename_component( tinyxml2_CONFIG_PATH ${tinyxml2_CONFIG_PATH} DIRECTORY ) set( tinyxml2_CONFIG_PATH ${tinyxml2_CONFIG_PATH}/build/${tinyxml2_HASH} ) set( tinyxml2_CONFIG_FILENAME tinyxml2Config.cmake ) find_file( tinyxml2_CONFIG_DIR ${tinyxml2_CONFIG_FILENAME} HINTS ${tinyxml2_CONFIG_PATH} ) if( tinyxml2_CONFIG_DIR-NOTFOUND ) set( tinyxml2_CONFIG "" ) else() set( tinyxml2_CONFIG ${tinyxml2_CONFIG_DIR} ) endif() mark_as_advanced( tinyxml2_INCLUDE_DIR tinyxml2_LIBRARY tinyxml2_DIR tinyxml2_CONFIG ) else() set( tinyxml2_DIR "" CACHE STRING "An optional hint to a tinyxml2 directory" ) endif()
Build
$ git clone https://gist.github.com/caiorss/351e291b8df2b0fc8e1bba5c86b7ee4d gist $ cd gist # Build with QT Creator $ qtcreator CMakeLists.txt # Build from command line $ cmake -H. -Bbuild -DCMAKE_BUILD_TYPE=Debug $ cmake --build build --target
Program Output:
- Meaning: USD 1.127 => Means that 1 Euro = 1.127 USD or that the exchange rate is 1.127 per Euro.
$ build/bin/tinyxml2-test [INFO] Running TinyXMl2 [OK] XML parsed successfully Value: doc.FirstChild()->Value() = xml version="1.0" encoding="UTF-8" Element found. OK =>> Element Name = gesmes:Envelope =>> Found Node Name: Cube => Time = 2019-06-14 ===== Exchange rates per Euros ==== USD 1.127 JPY 121.900 BGN 1.956 CZK 25.540 DKK 7.468 GBP 0.891 HUF 321.530 PLN 4.253 RON 4.723 SEK 10.639 CHF 1.121 ISK 141.500 NOK 9.773 HRK 7.410 RUB 72.388 TRY 6.643 AUD 1.632 BRL 4.342 CAD 1.502 CNY 7.800 HKD 8.817 IDR 16128.100 ILS 4.052 INR 78.608 KRW 1333.600 MXN 21.607 MYR 4.698 NZD 1.724 PHP 58.539 SGD 1.540 THB 35.101 ZAR 16.653
1.8.2 PugiXML - Lightweight XML parser
PugiXML is lightweight XML parsing library with DOM (Document Object Model) transversing and XPATH capabilities.
Official Web Site:
Documentation:
Repository:
Conan Reference:
Example:
File: pugixml_test1.cpp
#include <iostream> #include <iomanip> #include <string> #include <sstream> #include <pugixml.hpp> extern const char* exchangeRatesXML; int main() { // This input stream 'is' can be replaced by // any other input stream without any code modification // such as: std::ifstream is("/tmp/input-file.xml") std::stringstream is{exchangeRatesXML}; pugi::xml_document doc; pugi::xml_parse_result result = doc.load(is); if(!result){ std::cerr << " [ERROR] Failed to parse the XML. Invalid file." << std::endl; std::exit(EXIT_FAILURE); } std::string sender_name = doc.child("gesmes:Envelope") .child("gesmes:Sender") .child_value("gesmes:name"); // type: const char* auto subject = doc.child("gesmes:Envelope") .child_value("gesmes:subject"); auto time = doc.child("gesmes:Envelope") .child("Cube") .child("Cube").attribute("time") .value(); std::cout << " ========= DOCUMENT INFO ================" << std::endl; std::cout << " => Sender name = " << sender_name << std::endl; std::cout << " => Subject = " << subject << std::endl; std::cout << " => Time = " << time << std::endl; auto parent = doc.child("gesmes:Envelope") .child("Cube") .child("Cube"); std::cout << std::fixed << std::setprecision(3); std::cout <<"\n Exchange Rates per EURO " << std::endl; for(auto const& node : parent) { std::cout << std::setw(10) << node.attribute("currency").value() << std::setw(10) << std::stod(node.attribute("rate").value()) << std::endl; } std::cout << "\n\n *********** Extracting Data with XPATH ********\n\n"; pugi::xpath_node sender_name2 = doc.select_node("//gesmes:name"); std::cout << " Sender = " << sender_name2.node().child_value() << std::endl; auto time2 = doc.select_node("//Cube[@time]"); std::cout << " Time = " << time2.node().attribute("time").value() << std::endl; std::cout <<"\n Exchange Rates per EURO - Extracted with XPATH " << std::endl; // Type: pugi::xpath_node_set auto dataNodes = doc.select_nodes("/gesmes:Envelope/Cube/Cube/Cube"); for(auto const& n : dataNodes) { std::cout << std::setw(10) << n.node().attribute("currency").value() << std::setw(10) << std::stod(n.node().attribute("rate").value()) << std::endl; } return 0; } // Source: https://www.ecb.europa.eu/stats/eurofxref/eurofxref-daily.xml const char* exchangeRatesXML = R"( <?xml version="1.0" encoding="UTF-8"?> <gesmes:Envelope xmlns:gesmes="http://www.gesmes.org/xml/2002-08-01" xmlns="http://www.ecb.int/vocabulary/2002-08-01/eurofxref"> <gesmes:subject>Reference rates</gesmes:subject> <gesmes:Sender> <gesmes:name>European Central Bank</gesmes:name> </gesmes:Sender> <Cube> <Cube time='2019-06-14'> <Cube currency='USD' rate='1.1265'/> <Cube currency='JPY' rate='121.90'/> <Cube currency='BGN' rate='1.9558'/> <Cube currency='CZK' rate='25.540'/> <Cube currency='DKK' rate='7.4676'/> <Cube currency='GBP' rate='0.89093'/> <Cube currency='HUF' rate='321.53'/> <Cube currency='PLN' rate='4.2534'/> <Cube currency='RON' rate='4.7233'/> <Cube currency='SEK' rate='10.6390'/> <Cube currency='CHF' rate='1.1211'/> <Cube currency='ISK' rate='141.50'/> <Cube currency='NOK' rate='9.7728'/> <Cube currency='HRK' rate='7.4105'/> </Cube> </Cube> </gesmes:Envelope> )";
File: CMakeLists.txt
cmake_minimum_required(VERSION 3.9) project(purgixml) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) # ============= Conan Boosttrap =========================# # Download automatically, you can also just copy the conan.cmake file if(NOT EXISTS "${CMAKE_BINARY_DIR}/conan.cmake") message(STATUS "Downloading conan.cmake from https://github.com/conan-io/cmake-conan") file(DOWNLOAD "https://github.com/conan-io/cmake-conan/raw/v0.13/conan.cmake" "${CMAKE_BINARY_DIR}/conan.cmake") endif() include(${CMAKE_BINARY_DIR}/conan.cmake) # Possible values "default" and "llvm8" set(CONAN_PROFILE default) conan_cmake_run(REQUIRES pugixml/1.9@bincrafters/stable BASIC_SETUP BUILD missing) # ============= Find Package ===========================# find_package(pugixml REQUIRED) #============= Targets Settings ========================# add_executable(pugixml_test1 pugixml_test1.cpp) target_link_libraries(pugixml_test1 pugixml)
Program output:
========= DOCUMENT INFO ================
=> Sender name = European Central Bank
=> Subject = Reference rates
=> Time = 2019-06-14
Exchange Rates per EURO
USD 1.127
JPY 121.900
BGN 1.956
CZK 25.540
DKK 7.468
GBP 0.891
HUF 321.530
PLN 4.253
RON 4.723
SEK 10.639
CHF 1.121
ISK 141.500
NOK 9.773
HRK 7.410
*********** Extracting Data with XPATH ********
Sender = European Central Bank
Time = 2019-06-14
Exchange Rates per EURO - Extracted with XPATH
USD 1.127
JPY 121.900
BGN 1.956
CZK 25.540
DKK 7.468
GBP 0.891
HUF 321.530
PLN 4.253
RON 4.723
SEK 10.639
CHF 1.121
ISK 141.500
NOK 9.773
HRK 7.410
1.8.3 nlohmann JSON Parser Library
Easy to use single-file header-only library for parsing and writing JSON (Javascript Object Notation).
- Library Repository:
- Conan Recipe Repository:
- Conan Reference:
Example:
- File: CMakeLists.txt
- Version with Conan
cmake_minimum_required(VERSION 3.14 FATAL_ERROR) project(cppjson) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) # ============= Conan Bootstrap =============================# # Download automatically, you can also just copy the conan.cmake file if(NOT EXISTS "${CMAKE_BINARY_DIR}/conan.cmake") message(STATUS "Downloading conan.cmake from https://github.com/conan-io/cmake-conan") file(DOWNLOAD "https://github.com/conan-io/cmake-conan/raw/v0.13/conan.cmake" "${CMAKE_BINARY_DIR}/conan.cmake") endif() include(${CMAKE_BINARY_DIR}/conan.cmake) conan_cmake_run(REQUIRES jsonformoderncpp/3.7.0@vthiery/stable BASIC_SETUP BUILD missing ) #===== Targets ===========================# # Conan package: jsonformoderncpp/3.7.0@vthiery/stable find_package(nlohmann_json 3.2.0 REQUIRED) add_executable(json-parse json-parse.cpp) target_link_libraries(json-parse nlohmann_json::nlohmann_json)
- File: CMakeLists.txt
- Version without Conan with custom macro
cmake_minimum_required(VERSION 3.14 FATAL_ERROR) project(cmake-experiment) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) macro(Download_Single_Headerlib_dir FILE PATH URL) file(DOWNLOAD ${URL} ${CMAKE_BINARY_DIR}/include/${PATH}${FILE}) IF(NOT Download_Single_Headerlib_flag) include_directories(${CMAKE_BINARY_DIR}/include) set(Download_Single_Headerlib_flag TRUE) ENDIF() endmacro() # #include <nlohmann/json.hpp> Download_Single_Headerlib_dir( json.hpp "nlohmann/" "https://github.com/nlohmann/json/raw/develop/single_include/nlohmann/json.hpp" ) # --------------------------------------------# add_executable(json-parse json-parse.cpp)
- File: json-parse.cpp
#include <iostream> #include <sstream> #include <nlohmann/json.hpp> using json = nlohmann::json; int main() { std::puts("\n====== EXPERIMETN 1 - Create JSON Object ==========================="); { json top; top["hero1"] = "John Von Neumman / Modern Computers"; top["hero2"] = "Dennis Ritchie / C Language"; top["points"] = 200; top["list_number"] = {1, 2, 3, 3, 4, 5, 6}; top["list_string"] = {"Rice", "Coffee", "Beans", "Milk"}; top["currency_basket"] = {{"USD", 10}, {"BRL", 2000}, {"CAD", 90}, {"AUD", "N/A"}}; json cd; cd["latitude"] = -23.5505; cd["longitude"] = -46.6333; cd["location"] = "São Paulo city"; top["coordiante"] = cd; std::cout << "\n VALUE OF JSON [NOT PRETTY PRINT] = " << top << std::endl; std::cout << "\n VALUE OF JSON [PRETTY PRINT] = " << top.dump(4) << std::endl; } std::puts("\n====== EXPERIMETN 2 - Deserialization from string literal ==========="); { json d; try { // Parsing from string literal d = R"( { "x" : 1956.2322 , "y" : 1000 , "name" : "Dennis Ritchie" , "fruits" : [ "orange", "jabuticaba", "banana", "apple" ] , "basket" : { "BONDS": 1235, "CDS": 200.354, "FX": 500 , "market": "Emergin Markets"} } )"_json; } catch(nlohmann::detail::parse_error& ex) { std::cout << " [ERROR] I cannot parse it: " << ex.what() << std::endl; } std::cout << "\n VALUE OF JSON PRETTY PRINT = " << d.dump(3) << std::endl; std::cout << " [RESULT] x = " << static_cast<double>(d["x"]) << std::endl; std::cout << " [RESULT] x = " << d["x"].get<double>() << std::endl; std::cout << " [RESULT] y = " << d["y"].get<int>() << std::endl; std::cout << " [RESULT] name = " << d["name"].get<std::string>() << std::endl; std::cout << " [RESULT] fruit[0] = " << d["fruits"][0] << std::endl; std::cout << " [RESULT] fruit[1] = " << d["fruits"][1] << std::endl; std::cout << " [RESULT] fruit[2] = " << d["fruits"][2].get<std::string>() << std::endl; std::cout << " [RESULT] d['basket']['BONDS'] = " << d["basket"]["BONDS"].get<int>() << std::endl; std::cout << " [RESULT] d['basket']['CDS'] = " << d["basket"]["CDS"].get<double>() << std::endl; std::cout << " [RESULT] d['basket']['market'] = " << d["basket"]["market"].get<std::string>() << std::endl; // Attempt to generate a parser error try { // Note: Expects failure, the exception will be thrown! double value = static_cast<double>(d["name"]); std::cout << " [RESULT] 2 * x = " << 2 * value << "\n\n"; } catch (nlohmann::detail::type_error& ex) { std::cout << " [ERROR] err = " << ex.what() << std::endl; } } std::puts("\n====== EXPERIMETN 3 - Deserialization from stream ==========="); { const char* json_text = R"( { "x" : 1956.2322 , "y" : 1000 , "flag" : true , "name" : "Dennis Ritchie" , "asset_basket" : { "CAD": 100, "BRL": 200, "USD": 500} } )"; json js; /* Input stream could be a file: * auto is = std::ifstream("/tmp/file"); *------------------------------------------*/ auto is = std::stringstream(json_text); is >> js; // Extract from memory stream std::cout << std::boolalpha; std::cout << " JSON VALUE = " << js.dump(4) << std::endl; std::cout << " => is_null(x) = " << js["x"].is_null() << std::endl; std::cout << " => is_boolean(x) = " << js["x"].is_boolean() << std::endl; std::cout << " => is_number(x) = " << js["x"].is_number() << std::endl; std::cout << " => is_string(name) = " << js["name"].is_string() << std::endl; std::cout << " => is_string(asset_basket) = " << js["asset_basket"].is_string() << std::endl; std::cout << " => is_object(asset_basket) = " << js["asset_basket"].is_object() << std::endl; std::puts("\n >>>--|>>> Iterate Over JSON AST - Abstract Syntax Tree <<<|---<<< "); for(auto const& element: js) std::cout << " => element = " << element << std::endl; } }
Output:
====== EXPERIMETN 1 - Create JSON Object ===========================
VALUE OF JSON [NOT PRETTY PRINT] = {"coordiante":{"latitude":-23.5505,"location":"São Paulo city","longitude":-46.6333}, ....}
VALUE OF JSON [PRETTY PRINT] = {
"coordiante": {
"latitude": -23.5505,
"location": "São Paulo city",
"longitude": -46.6333
},
"currency_basket": {
"AUD": "N/A",
"BRL": 2000,
"CAD": 90,
"USD": 10
},
"hero1": "John Von Neumman / Modern Computers",
"hero2": "Dennis Ritchie / C Language",
"list_number": [
1,
2,
3,
3,
4,
5,
6
],
"list_string": [
"Rice",
"Coffee",
"Beans",
"Milk"
],
"points": 200
}
====== EXPERIMETN 2 - Deserialization from string literal ===========
VALUE OF JSON PRETTY PRINT = {
"basket": {
"BONDS": 1235,
"CDS": 200.354,
"FX": 500,
"market": "Emergin Markets"
},
"fruits": [
"orange",
"jabuticaba",
"banana",
"apple"
],
"name": "Dennis Ritchie",
"x": 1956.2322,
"y": 1000
}
[RESULT] x = 1956.23
[RESULT] x = 1956.23
[RESULT] y = 1000
[RESULT] name = Dennis Ritchie
[RESULT] fruit[0] = "orange"
[RESULT] fruit[1] = "jabuticaba"
[RESULT] fruit[2] = banana
[RESULT] d['basket']['BONDS'] = 1235
[RESULT] d['basket']['CDS'] = 200.354
[RESULT] d['basket']['market'] = Emergin Markets
[ERROR] err = [json.exception.type_error.302] type must be number, but is string
====== EXPERIMETN 3 - Deserialization from stream ===========
JSON VALUE = {
"asset_basket": {
"BRL": 200,
"CAD": 100,
"USD": 500
},
"flag": true,
"name": "Dennis Ritchie",
"x": 1956.2322,
"y": 1000
}
=> is_null(x) = false
=> is_boolean(x) = false
=> is_number(x) = true
=> is_string(name) = true
=> is_string(asset_basket) = false
=> is_object(asset_basket) = true
>>>--|>>> Iterate Over JSON AST - Abstract Syntax Tree <<<|---<<<
=> element = {"BRL":200,"CAD":100,"USD":500}
=> element = true
=> element = "Dennis Ritchie"
=> element = 1956.2322
=> element = 1000
1.8.4 cpptoml configuration parser
cpptoml is a single-file header-only library for parsing TOML configuration files that resembles the Windows INI files and are more lightweight than XML and JSON.
Repository:
Download the library:
$ cd <PROJECT_DIR> $ curl -O -L https://raw.githubusercontent.com/skystrife/cpptoml/v0.1.1/include/cpptoml.h
File: main.cpp
#include <iostream> #include <string> #include <sstream> #include <cpptoml.h> template <typename T> using sh = std::shared_ptr<T>; extern const char* tomlData; void parseConfiguration(std::istream& is) { cpptoml::parser p{is}; sh<cpptoml::table> config = p.parse(); std::cout << "\n --- TOML Configuration data read from input stream ------\n"; int loglevel = config->get_qualified_as<int>("INFO.loglevel").value_or(0); auto userName = config->get_qualified_as<std::string>("INFO.user").value_or("unnamed"); auto file = config->get_qualified_as<std::string>("INFO.file").value_or(""); auto port = config->get_qualified_as<int>("SERVER.port").value_or(8080); std::cout << " => loglevel = " << loglevel << "\n" << " => userName = " << userName << "\n" << " => file = " << file << "\n" << " => port = " << port << "\n"; auto locations = config->get_qualified_array_of<std::string>("SERVER.directories"); if(!locations) { std::cerr << " [ERROR] SERVER.directories not found." << std::endl; } for(auto const& path: *locations) { std::cout << " path: " << path << std::endl; } } int main(int argc, char** argv) { if(argc == 1){ std::cerr << " Error: invalid option " << std::endl; return EXIT_FAILURE; } std::string cmd = argv[1]; if(cmd == "-stream") { auto is = std::stringstream(tomlData); parseConfiguration(is); return EXIT_SUCCESS; } if(cmd == "-file" && argc == 3) { auto is = std::ifstream(argv[2]); if(!is){ std::cerr << "Error: file not found." << std::endl; std::exit(EXIT_FAILURE); } parseConfiguration(is); return EXIT_SUCCESS; } std::cerr << " Error: invalid option. " << std::endl; return 0; } const char* tomlData = R"( [INFO] loglevel = 10 user = "Dummy user" file = "C:\\Users\\somebody\\storage\\data.log" [SERVER] host = "127.0.0.1" port = 9090 directories = [ "C:\\Users\\somebody\\Document" ,"C:\\Users\\somebody\\Upload" ,"C:\\Users\\somebody\\Pictures" ] )";
File: server.conf
[INFO]
loglevel = 0
user = "Admin User"
file = "C:\\Users\\admin\\files\\log.txt"
[SERVER]
host = "0.0.0.0"
port = 9060
directories = [
"/Users/admin/Desktop"
,"/Applications"
,"/Frameworks"
,"/tmp"
]
Building:
$ g++ main.cpp -o main.bin -std=c++1z -g -O0 -Wall -Wextra -pedantic # Mesaure compile-time $ time g++ main.cpp -o main.bin -std=c++1z -g -O0 -Wall -Wextra -pedantic real 0m2.462s user 0m2.262s sys 0m0.172s
Parse internal data (std::istream):
$ ./main.bin -stream --- TOML Configuration data read from input stream ------ => loglevel = 10 => userName = Dummy user => file = C:\Users\somebody\storage\data.log => port = 9090 path: C:\Users\somebody\Document path: C:\Users\somebody\Upload path: C:\Users\somebody\Pictures
Parse file (std::ifstream):
$ ./main.bin -file server.conf --- TOML Configuration data read from input stream ------ => loglevel = 0 => userName = Admin User => file = C:\Users\admin\files\log.txt => port = 9060 path: /Users/admin/Desktop path: /Applications path: /Frameworks path: /tmp
1.9 Unit Testing
1.9.1 GTest - Unit Testing Framework
GTest or Google test is one of the most used and most popular test frameworks which supports many features such as mocks; test fixtures; parameterized tests; XML test report in JUnit / xUnit format; test discovery and integration with IDEs, namely Eclipse, QTCreator and Visual Studio.
Official Web site:
Some Tutorial/Primers:
- Google Test Primer (Official)
- How to use Google Test for C++ - Visual Studio | Microsoft Docs
- GoogleTest: C++ unit test framework
- A quick introduction to the Google C++ Testing Framework – IBM Developer
Conan Reference:
Test Runner for GTest:
CMake Integration:
Fatal Assertions:
- ASSERT_TRUE
- ASSERT_FALSE
- ASSERT_EQ(val1, val2)
- ASSERT_NE(val1, val2)
- ASSERT_LT
- ASSERT_GT
- ASSERT_GE
Non-fatal assertions Macros:
- EXPECT_TRUE
- EXPECT_FALSE
- EXPECT_EQ
- EXPECT_NQ
- EXPECT_DOUBLE_EQ
- EXPECT_FLOAT_EQ
- EXPECT_NEAR(value1, value2, absolute_tolerance)
- TEST(<NAME>, ){ … <BODY> .. }
- EXPECT_FLOAT_EQ
Example: Usage with CMake and QTCreator
Get the source code:
$ git clone https://gist.github.com/caiorss/eb2fc15b7ed322ccac5ee496585e54e9 gist && cd gist Cloning into 'gist'... remote: Enumerating objects: 4, done. remote: Counting objects: 100% (4/4), done. remote: Compressing objects: 100% (4/4), done. remote: Total 4 (delta 0), reused 0 (delta 0), pack-reused 0 Unpacking objects: 100% (4/4), done. $ ls CMakeLists.txt gtest-experiment.cpp # Open with QT Creator, Visual Studio or build from command line $ qtcreator CMakeList.txt # Open with Visual Studio $ devenv CMakeLists.txt
File: gtest-experiment.cpp
Headers:
#include <iostream> #include <string> #include <vector> #include <cassert> #include <gtest/gtest.h>
Implementations:
// ==================== Implementation ======================== int factorial(int n){ int prod = 1; for(int i = 1; i <= n; i++) prod *= i; return prod; } struct Date { int year; int month; int day; Date(){} Date(int year, int month, int day) : year(year) , month(month) , day(day) { } // Comparison operator required by EXPECT_EQ bool operator==(Date const& rhs) const { return year == rhs.year && month == rhs.month && day == rhs.day; } // Necessary for make class printable in GTest friend std::ostream& operator<<(std::ostream& os, Date const& rhs) { return os << "Date { " << rhs.year << " ; " << rhs.month << " ; " << rhs.day << " } "; } }; Date GregorianEasterSunday(int y) { int c = y / 100; int n = y - 19 * ( y / 19 ); int k = ( c - 17 ) / 25; int i = c - c / 4 - ( c - k ) / 3 + 19 * n + 15; i = i - 30 * ( i / 30 ); i = i - ( i / 28 ) * ( 1 - ( i / 28 ) * ( 29 / ( i + 1 ) ) * ( ( 21 - n ) / 11 ) ); int j = y + y / 4 + i + 2 - c + c / 4; j = j - 7 * ( j / 7 ); int l = i - j; int m = 3 + ( l + 40 ) / 44; int d = l + 28 - 31 * ( m / 4 ); return Date(y, m, d); }
Test code:
//=============== Tests ====================================// TEST(FactorialTest, test1){ EXPECT_EQ(6, factorial(3)); EXPECT_EQ(24, factorial(4)); EXPECT_EQ(120, factorial(5)); EXPECT_EQ(3628800, factorial(10)); // Expect greater than EXPECT_GT(10000000, factorial(10)); // Expect not equal EXPECT_NE(25, factorial(4)); } TEST(FactorialTestFailure, testFailure){ // Deliberately fails for demonstration purposes EXPECT_EQ(6, factorial(3)); EXPECT_EQ(4, factorial(4)); EXPECT_EQ(6, factorial(2)); } TEST(GregorianEaster, testdates){ EXPECT_EQ(Date(2005, 3, 27), GregorianEasterSunday(2005)); EXPECT_EQ(Date(2008, 3, 23), GregorianEasterSunday(2008)); EXPECT_EQ(Date(2010, 4, 4), GregorianEasterSunday(2010)); }
File: CMakeLists.txt
cmake_minimum_required(VERSION 3.9) project( GtestsExperiment VERSION 0.1 DESCRIPTION "Experiment with Gtest uni testing framework" ) # ============= Conan Bootstrap =============================# # Download automatically, you can also just copy the conan.cmake file if(NOT EXISTS "${CMAKE_BINARY_DIR}/conan.cmake") message(STATUS "Downloading conan.cmake from https://github.com/conan-io/cmake-conan") file(DOWNLOAD "https://github.com/conan-io/cmake-conan/raw/v0.13/conan.cmake" "${CMAKE_BINARY_DIR}/conan.cmake") endif() include(${CMAKE_BINARY_DIR}/conan.cmake) conan_cmake_run(REQUIRES gtest/1.8.1@bincrafters/stable BASIC_SETUP BUILD missing ) #============= Find Packages ================================# find_package(GTest REQUIRED) #---------------------------------------------------# # Targets Settings # #---------------------------------------------------# add_executable(gtest-experiment gtest-experiment.cpp) target_link_libraries(gtest-experiment GTest::GTest GTest::Main) add_test(GTestExperiment gtest-experiment)
Test Output:
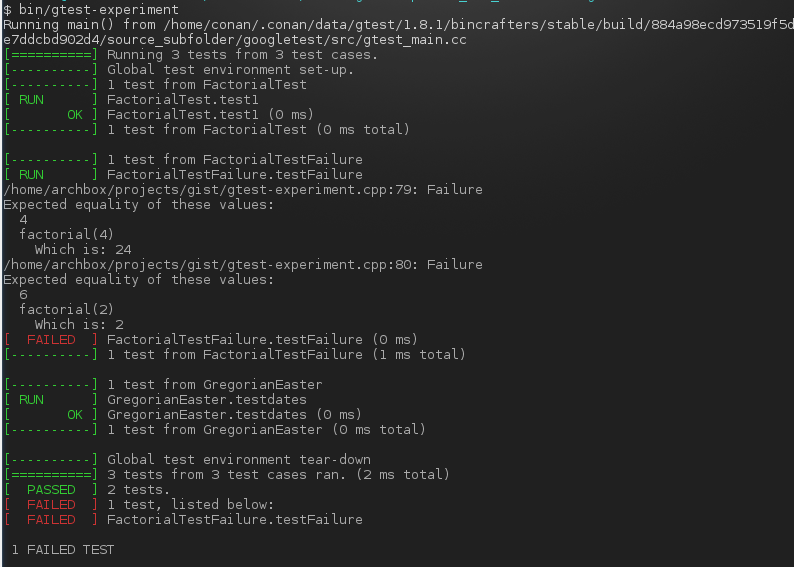
Figure 1: Test output in Command Line
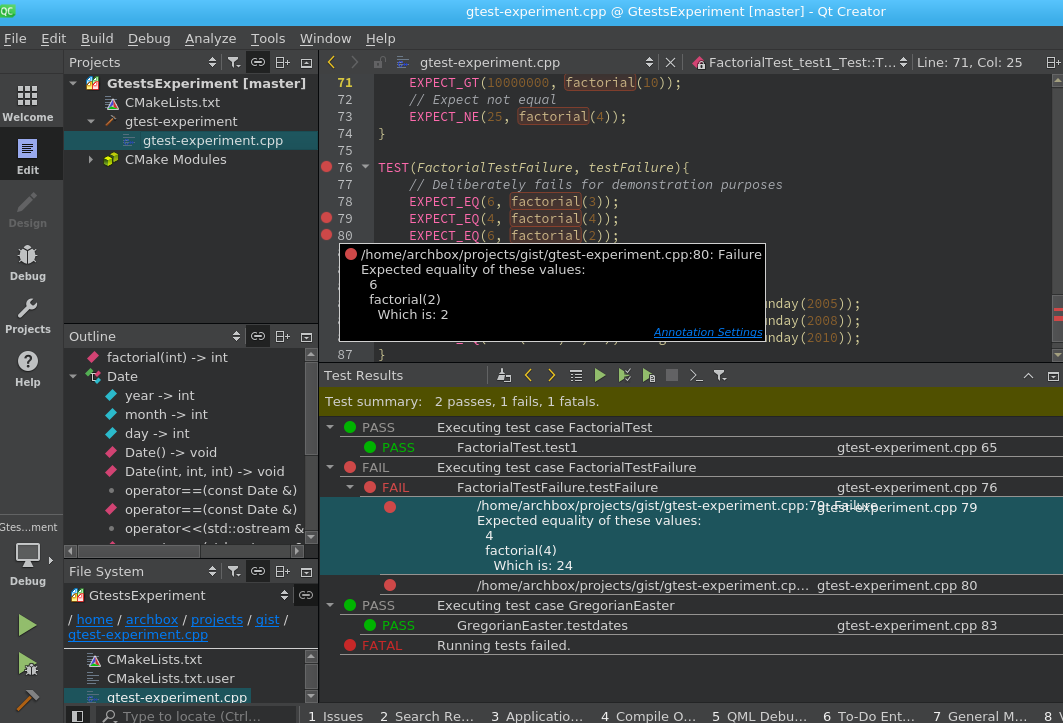
Figure 2: QTCreator Test Discovery
1.9.2 Catch2 - Unit Testing Framework
Advatanges over other test frameworks:
- Header-only library, so it requires no linking step or linking dependencies.
- Uses C++ operators instead of many macros such as (X > 20) instead of EXPECT_GT(X, 20) (expect grater than) as in GTest (Google's test)
- BDD - Behavior Driven Development
- Property-based testing - testing with several random values and combination of random values.
- Test with multiple data or data table which frees the user from writing lots boilerplate ASSERT_EQUAL(x, y). A single REQUIRE macro can be used for test a whole list of cartesian pairs such as (x, y,z, expected)
- XML output in JUnit, xUnit format.
Problem:
- Compile-time can be a bit slow due to the library be header-only.
Repository:
Conan Reference:
Code Examples:
- https://github.com/catchorg/Catch2/tree/master/examples
- Test Generators - testing with multiple data
Tutorial:
- Catch2/tutorial.md at master · catchorg/Catch2 · GitHub
- Writing C++ unit tests with Catch2 - BDD - Behavior Driven Development.
Misc:
Example simple test:
File: testcatch2.cpp
#include <iostream> #include <catch2/catch.hpp> int formula(int x, int y) { return 4 * x + 2 * y; } TEST_CASE("Test function furmula A", "[tag1]") { REQUIRE( formula(3, 4) == 20 ); REQUIRE( formula(4, 5) == 26 ); } TEST_CASE("Test function formula B", "[tag2]") { REQUIRE( formula(0, 0) == 0 ); // Intentionally fails REQUIRE( formula(2, 5) == 10 ); } struct TestData { int x, y, expected; }; TEST_CASE("Testing with struct") { auto t = GENERATE( values<TestData>( { {3, 4, 20} ,{4, 5, 26} ,{0, 0, 0} ,{-1, 4, 6} // Fails ,{ 2, 2, 12} })); REQUIRE( formula(t.x, t.y) == t.expected); } TEST_CASE("Testing with structured bindings") { auto [x, y, z] = GENERATE( table<int, int, int>( { {3, 4, 20} ,{4, 5, 26} ,{0, 0, 0} ,{2, 2, 12} })); REQUIRE( formula(x, y) == z); }
File: CMakeLists.txt - CMake building script integrated with Conan.
cmake_minimum_required(VERSION 3.9) project(Catch2_testing) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) # ============= Conan Bootstrap =============================# # Download automatically, you can also just copy the conan.cmake file if(NOT EXISTS "${CMAKE_BINARY_DIR}/conan.cmake") message(STATUS "Downloading conan.cmake from https://github.com/conan-io/cmake-conan") file(DOWNLOAD "https://github.com/conan-io/cmake-conan/raw/v0.13/conan.cmake" "${CMAKE_BINARY_DIR}/conan.cmake") endif() include(${CMAKE_BINARY_DIR}/conan.cmake) conan_cmake_run(REQUIRES Catch2/2.7.2@catchorg/stable BASIC_SETUP BUILD missing ) #============= Find Packages ================================# find_package(Catch2 REQUIRED) #---------------------------------------------------# # Targets Settings # #---------------------------------------------------# add_executable(testcatch2 testcatch2.cpp test-main.cpp) target_link_libraries(testcatch2)
Test runner help option:
$ ./testcatch2 -h Catch v2.7.2 usage: testcatch2 [<test name|pattern|tags> ... ] options where options are: -?, -h, --help display usage information -l, --list-tests list all/matching test cases -t, --list-tags list all/matching tags -s, --success include successful tests in output -b, --break break into debugger on failure -e, --nothrow skip exception tests -i, --invisibles show invisibles (tabs, newlines) -o, --out <filename> output filename -r, --reporter <name> reporter to use (defaults to console) -n, --name <name> suite name -a, --abort abort at first failure -x, --abortx <no. failures> abort after x failures -w, --warn <warning name> enable warnings -d, --durations <yes|no> show test durations -f, --input-file <filename> load test names to run from a file -#, --filenames-as-tags adds a tag for the filename -c, --section <section name> specify section to run -v, --verbosity <quiet|normal|high> set output verbosity --list-test-names-only list all/matching test cases names only --list-reporters list all reporters --order <decl|lex|rand> test case order (defaults to decl) --rng-seed <'time'|number> set a specific seed for random numbers --use-colour <yes|no> should output be colourised --libidentify report name and version according to libidentify standard --wait-for-keypress <start|exit|both> waits for a keypress before exiting --benchmark-resolution-multiple multiple of clock resolution to <multiplier> run benchmarks For more detailed usage please see the project docs
Test runner test list:
$ ./testcatch2 --list-tests All available test cases: Test function furmula A [tag1] Test function formula B [tag2] Testing with struct Testing with structured bindings 4 test cases
Test runner output:
$ ./testcatch2 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ testcatch2 is a Catch v2.7.2 host application. Run with -? for options ------------------------------------------------------------------------------- Test function formula B ------------------------------------------------------------------------------- /home/archbox/Documents/projects/fquant/testcatch2.cpp:17 ............................................................................... /home/archbox/Documents/projects/fquant/testcatch2.cpp:21: FAILED: REQUIRE( formula(2, 5) == 10 ) with expansion: 18 == 10 ------------------------------------------------------------------------------- Testing with struct ------------------------------------------------------------------------------- /home/archbox/Documents/projects/fquant/testcatch2.cpp:31 ............................................................................... /home/archbox/Documents/projects/fquant/testcatch2.cpp:41: FAILED: REQUIRE( formula(t.x, t.y) == t.expected ) with expansion: 4 == 6 =============================================================================== test cases: 4 | 2 passed | 2 failed assertions: 13 | 11 passed | 2 failed
1.9.3 Doctest - Unit Testing Framewok
Doctest is a unit test framework based on catch2 test framework, however doctest has a much faster compile-time than many other unit-test frameworks.
Advantages:
- Easy of use
- Faster compile-time
- Easy to integrate, header-only-library
- Operator based testing: CHECK(VALUE == EXPECTED), CHECK(x > 10) instead of No need to use macros ASSERT_EQ, ASSERT_NEQ (not equal) as in GTest.
Disadvantages:
- No XML output with jUnit standard similar to GTest standard.
- No integration with IDE
- No data-driven test, aka parameterized test, or test with a list of value tuples.
Repository:
Conan Reference:
Conan Package:
Code Examples:
Features:
See:
- ACCU - doctest – the Lightest C++ Unit Testing Framewor
- doctest - the lightest C++ unit testing framework - CodeProject
Video:
Usage:
- File: doctest_experiment.cpp
#define DOCTEST_CONFIG_IMPLEMENT_WITH_MAIN #include <doctest.h> int formula(int x, int y) { return 4 * x + 2 * y; } TEST_CASE("Test function furmula A") { CHECK( formula(3, 4) == 20 ); CHECK( formula(4, 5) == 26 ); CHECK( formula(4, 5) < 100 ); CHECK( formula(4, 5) != 0 ); } TEST_CASE("Test function formula B") { CHECK( formula(0, 0) == 0 ); // Intentionally fails CHECK( formula(2, 5) == 10 ); }
- File: CMakeLists.txt integrated with Conan
cmake_minimum_required(VERSION 3.9) project( doctest_experiment VERSION 0.1 DESCRIPTION "A doctest experiment" ) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) # ============= Conan Bootstrap =============================# # Download automatically, you can also just copy the conan.cmake file if(NOT EXISTS "${CMAKE_BINARY_DIR}/conan.cmake") message(STATUS "Downloading conan.cmake from https://github.com/conan-io/cmake-conan") file(DOWNLOAD "https://github.com/conan-io/cmake-conan/raw/v0.13/conan.cmake" "${CMAKE_BINARY_DIR}/conan.cmake") endif() include(${CMAKE_BINARY_DIR}/conan.cmake) conan_cmake_run(REQUIRES doctest/2.3.1@bincrafters/stable BASIC_SETUP BUILD missing ) #============= Find Packages ================================# find_package(doctest 2.3.1 REQUIRED) #---------------------------------------------------# # Targets Settings # #---------------------------------------------------# add_executable(doctest_experiment doctest_experiment.cpp) copy_after_build(doctest_experiment) # target_link_libraries(doctest_experiment doctest::doctest)
Show options:
$ bin/doctest_experiment -h [doctest] doctest version is "2.3.1" [doctest] [doctest] boolean values: "1/on/yes/true" or "0/off/no/false" [doctest] filter values: "str1,str2,str3" (comma separated strings) [doctest] [doctest] filters use wildcards for matching strings [doctest] something passes a filter if any of the strings in a filter matches [doctest] [doctest] ALL FLAGS, OPTIONS AND FILTERS ALSO AVAILABLE WITH A "dt-" PREFIX!!! [doctest] [doctest] Query flags - the program quits after them. Available: -?, --help, -h prints this message -v, --version prints the version -c, --count prints the number of matching tests -ltc, --list-test-cases lists all matching tests by name -lts, --list-test-suites lists all matching test suites -lr, --list-reporters lists all registered reporters [doctest] The available <int>/<string> options/filters are: -tc, --test-case=<filters> filters tests by their name -tce, --test-case-exclude=<filters> filters OUT tests by their name -sf, --source-file=<filters> filters tests by their file -sfe, --source-file-exclude=<filters> filters OUT tests by their file -ts, --test-suite=<filters> filters tests by their test suite -tse, --test-suite-exclude=<filters> filters OUT tests by their test suite -sc, --subcase=<filters> filters subcases by their name -sce, --subcase-exclude=<filters> filters OUT subcases by their name -r, --reporters=<filters> reporters to use (console is default) -o, --out=<string> output filename -ob, --order-by=<string> how the tests should be ordered <string> - by [file/suite/name/rand] -rs, --rand-seed=<int> seed for random ordering -f, --first=<int> the first test passing the filters to execute - for range-based execution -l, --last=<int> the last test passing the filters to execute - for range-based execution -aa, --abort-after=<int> stop after <int> failed assertions -scfl,--subcase-filter-levels=<int> apply filters for the first <int> levels [doctest] Bool options - can be used like flags and true is assumed. Available: -s, --success=<bool> include successful assertions in output -cs, --case-sensitive=<bool> filters being treated as case sensitive -e, --exit=<bool> exits after the tests finish -d, --duration=<bool> prints the time duration of each test -nt, --no-throw=<bool> skips exceptions-related assert checks -ne, --no-exitcode=<bool> returns (or exits) always with success -nr, --no-run=<bool> skips all runtime doctest operations -nv, --no-version=<bool> omit the framework version in the output -nc, --no-colors=<bool> disables colors in output -fc, --force-colors=<bool> use colors even when not in a tty -nb, --no-breaks=<bool> disables breakpoints in debuggers -ns, --no-skip=<bool> don't skip test cases marked as skip -gfl, --gnu-file-line=<bool> :n: vs (n): for line numbers in output -npf, --no-path-filenames=<bool> only filenames and no paths in output -nln, --no-line-numbers=<bool> 0 instead of real line numbers in output [doctest] for more information visit the project documentation
Test runner test listing:
$ bin/doctest_experiment --list-test-cases [doctest] listing all test case names =============================================================================== Test function furmula A Test function formula B ================================================
Run tests: (Note: It is printed with colored output)
$ bin/doctest_experiment [doctest] doctest version is "2.3.1" [doctest] run with "--help" for options =============================================================================== /home/archbox/Documents/projects/fquant/doctest_experiment.cpp:21: TEST CASE: Test function formula B /home/archbox/Documents/projects/fquant/doctest_experiment.cpp:25: ERROR: CHECK( formula(2, 5) == 10 ) is NOT correct! values: CHECK( 18 == 10 ) =============================================================================== [doctest] test cases: 2 | 1 passed | 1 failed | 0 skipped [doctest] assertions: 6 | 5 passed | 1 failed | [doctest] Status: FAILURE!
1.10 Google Benchmark
Overview: It is library for micro benchmarks of isolated parts of the code and comparison between algorithms performance.
Web Site:
- https://github.com/google/benchmark
- https://opensource.googleblog.com/2014/01/introducing-benchmark.html
Sample Project:
File: CmakeLists.txt
cmake_minimum_required(VERSION 2.8) project(gbench-evaluation) set(CMAKE_CXX_STANDARD 17) set(CMAKE_CXX_STANDARD_REQUIRED ON) set(CMAKE_VERBOSE_MAKEFILE ON) #========== Macros for automating Library Fetching =============# include(FetchContent) # Download library archive (zip, *.tar.gz, ...) from URL macro(Download_Library_Url NAME URL) FetchContent_Declare(${NAME} URL ${URL}) FetchContent_GetProperties(${NAME}) if(NOT ${NAME}_POPULATED) FetchContent_Populate(${NAME}) add_subdirectory(${${NAME}_SOURCE_DIR} ${${NAME}_BINARY_DIR}) endif() endmacro() #========== Library Download / Fetching ===========================# # Google Benchmark Build Setting set(BENCHMARK_ENABLE_TESTING OFF CACHE BOOL "" FORCE) set(BENCHMARK_ENABLE_GTEST_TESTS OFF CACHE BOOL "" FORCE) set(BENCHMARK_DOWNLOAD_DEPENDENCIES OFF CACHE BOOL "" FORCE) Download_Library_Url( gbenchmark "https://github.com/google/benchmark/archive/v1.5.0.zip" ) #========== Package Settings =====================================# add_executable(benchmark_runner bench.cpp) target_link_libraries(benchmark_runner PRIVATE benchmark)
File: bench.cpp
#include <iostream> #include <string> #include <cstdint> #include <cassert> #include <fstream> // Google Benchmark header #include <benchmark/benchmark.h> // #define ENABLE_LOGGING using ulong = unsigned long; //======= Implementations =================# auto fibonacci_recursive(ulong n) -> ulong { if(n < 2) { return 1; } return fibonacci_recursive(n - 1) + fibonacci_recursive(n - 2); } auto fibonacci_non_recursive(ulong n) -> ulong { ulong a = 0, b = 1, next = 0; if(n < 2) { return 1; } for(auto i = 0UL; i < n; ++i) { next = a + b; a = b; b = next; } return next; } //====== Benchmark Code ===================# /* Note: All benchmark functions must have this signature. * * using BenchmarkSignature = void (*) (benchmark::State& state) */ void BM_fibonacci_non_recursive(benchmark::State& state) { // std::cerr << " [NON RECURSIVE FIBONACCI] " << std::endl; while(state.KeepRunning()) { for(int64_t n = 0, n_end = state.range(); n < n_end; n++) { fibonacci_non_recursive(static_cast<ulong>(n)); // std::cerr << " n = " << n << " Result = " << fibonacci_non_recursive(static_cast<ulong>(n)) << std::endl; } } } // Register benchmark function // Possibility A: BENCHMARK(BM_fibonacci_non_recursive)->Range(0, 40); BENCHMARK(BM_fibonacci_non_recursive)->Arg(10)->Arg(30)->Arg(40)->Arg(45); #ifdef ENABLE_LOGGING auto sink = std::ofstream("logging.txt"); #endif void BM_fibonacci_recursive(benchmark::State& state) { // std::cerr << " [RECURSIVE FIBONACCI] " << std::endl; static int counter = 0; ulong result; #ifdef ENABLE_LOGGING sink << "\n [BM_fibonacci_recursive] counter = " << counter++ << std::endl; #endif while(state.KeepRunning()) { for(int64_t n = 0, n_end = state.range(); n < n_end; n++) { auto result = fibonacci_recursive(static_cast<ulong>(n)); #ifdef ENABLE_LOGGING sink << "n_end = " << n_end << " n = " << n << " Result = " << fibonacci_recursive(static_cast<ulong>(n)) << std::endl; #endif } } } // Register benchmark function BENCHMARK(BM_fibonacci_recursive)->Arg(10)->Arg(30)->Arg(40)->Arg(45); //=============== Entry Point - main() Function =====================// // Benchmark program entry point //---------------------------- // BENCHMARK_MAIN(); int main(int argc, char** argv) { std::cout << "========= Micro Benchmark ===============" << std::endl; benchmark::Initialize(&argc, argv); benchmark::RunSpecifiedBenchmarks(); return 0; }
Building
$ cmake -H. -B_build -DCMAKE_BUILD_TYPE=Release $ cmake --build _build --target
Running
$ _build/benchmark_runner ========= Micro Benchmark =============== 2019-08-28 14:53:53 Running _build/benchmark_runner Run on (4 X 3100 MHz CPU s) CPU Caches: L1 Data 32K (x2) L1 Instruction 32K (x2) L2 Unified 256K (x2) L3 Unified 4096K (x1) Load Average: 0.72, 0.81, 0.96 ***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead. ------------------------------------------------------------------------ Benchmark Time CPU Iterations ------------------------------------------------------------------------ BM_fibonacci_non_recursive/10 0.375 ns 0.373 ns 1000000000 BM_fibonacci_non_recursive/30 0.367 ns 0.366 ns 1000000000 BM_fibonacci_non_recursive/40 0.352 ns 0.351 ns 1000000000 BM_fibonacci_non_recursive/45 0.357 ns 0.356 ns 1000000000 BM_fibonacci_recursive/10 261 ns 260 ns 2531115 BM_fibonacci_recursive/30 4407109 ns 4396380 ns 159 BM_fibonacci_recursive/40 600690587 ns 598780692 ns 1 BM_fibonacci_recursive/45 6128444226 ns 6110706127 ns 1
1.11 Pistache - REST Http Web Server
Pistache is C++11 a web, http and rest framework, in other words, a C++ toolkit for building standalone web servers. This library is easy to use and fast to compile without any external dependency.
Web Site:
Repository:
Conan Coordinate:
Example:
File: CMakeLists.txt
cmake_minimum_required(VERSION 3.14 FATAL_ERROR) project(pistache-web-server) set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) # ============= Conan Bootstrap =============================# # Download automatically, you can also just copy the conan.cmake file if(NOT EXISTS "${CMAKE_BINARY_DIR}/conan.cmake") message(STATUS "Downloading conan.cmake from https://github.com/conan-io/cmake-conan") file(DOWNLOAD "https://github.com/conan-io/cmake-conan/raw/v0.13/conan.cmake" "${CMAKE_BINARY_DIR}/conan.cmake") endif() include(${CMAKE_BINARY_DIR}/conan.cmake) conan_cmake_run(REQUIRES pistache/d5608a1@conan/stable BASIC_SETUP BUILD missing ) # ========= Target Configurations =========================// add_executable(pistache-server pistache-server.cpp) target_link_libraries(pistache-server pistache)
File: pistache-server.cpp
#include <iostream> #include <string> #include <pistache/endpoint.h> namespace ps = Pistache; namespace Http = Pistache::Http; namespace Header = Pistache::Http::Header; // using namespace Pistache; std::ostream& operator<<(std::ostream& os, Http::Request const& req) { return os << " Method " << req.method() << "; route = " << req.resource() << "; body = " << req.body(); } struct HttpTransaction : public ps::Http::Handler { HTTP_PROTOTYPE(HttpTransaction) void onRequest(Http::Request const& req, Http::ResponseWriter res) override { std::cout << " Request: " << req << std::endl; // Set response headers res.headers().add<Header::Server>("CeePlusPlusWebServer"); // Route: / => Root if(req.method() == Http::Method::Get && req.resource() == "/") { res.send(Http::Code::Ok, " ==> Welcome to my C++ Web Server, Enjoy it"); return; } // Route: /demo1 if(req.method() == Http::Method::Get && req.resource() == "/demo1") { res.send(ps::Http::Code::Ok, R"( <html> <h1> C++ blazing fast web server. </h1> <img src='https://www.howtogeek.com/wp-content/uploads/2018/09/bin_lede.png.pagespeed.ce.cyJdjIBBg2.png' /> </html> )"); return; } // Route: /file => Serve Linux file /etc/protcols to client side if(req.method() == Http::Method::Get && req.resource() == "/file") { // Allows client side download the text file /etc/protocols Http::serveFile(res, "/etc/protocols"); return; } res.send(Http::Code::Not_Found, "Error: page not found in this server"); } }; int main() { std::puts(" [INFO] Starting server. "); auto addr = ps::Address{ // Allows connections from any IP address ps::Ipv4::any(), // Listen port 9080, aka bind to port 9080 ps::Port(9080) }; auto ops = ps::Http::Endpoint::options() .threads(4) .flags( ps::Tcp::Options::ReuseAddr); ps::Http::Endpoint server(addr); server.init(ops); server.setHandler(Http::make_handler<HttpTransaction>()); try { // Attempt to bind server to port server.serve(); } catch(std::runtime_error const& ex) { std::cout << " [ERROR] Unable to start server. => \n" << ex.what() << std::endl; } std::puts("Exit application. OK."); return 0; } // --- End of Main() ---------------------//
Running server:
$ ./bin/pistache-server [INFO] Starting server.
Server route: /
- Http request to URL:
http://localhost:9080/
$ curl localhost:9080 Welcome to my C++ Web Server, Enjoy it $ curl -v localhost:9080 * Rebuilt URL to: localhost:9080/ * Trying ::1... * TCP_NODELAY set * connect to ::1 port 9080 failed: Connection refused * Trying 127.0.0.1... * TCP_NODELAY set * Connected to localhost (127.0.0.1) port 9080 (#0) > GET / HTTP/1.1 > Host: localhost:9080 > User-Agent: curl/7.59.0 > Accept: */* > < HTTP/1.1 200 OK < Server: CeePlusPlusWebServer < Connection: Keep-Alive < Content-Length: 38 < * Connection #0 to host localhost left intact Welcome to my C++ Web Server, Enjoy it
- Server log:
Request: Method GET; route = /; body =
Server route: /errorrout
- Http request to URL:
http://localhost:9080/errorroute
$ curl http://localhost:9080/errorroute Error: page not found in this server $ curl -v http://localhost:9080/errorroute * Trying ::1... * TCP_NODELAY set * connect to ::1 port 9080 failed: Connection refused * Trying 127.0.0.1... * TCP_NODELAY set * Connected to localhost (127.0.0.1) port 9080 (#0) > GET /errorroute HTTP/1.1 > Host: localhost:9080 > User-Agent: curl/7.59.0 > Accept: */* > < HTTP/1.1 404 Not Found < Server: CeePlusPlusWebServer < Connection: Keep-Alive < Content-Length: 36 < * Connection #0 to host localhost left intact Error: page not found in this server
Server route: /demo1
- Http request to URL:
http://localhost:9080/demo1
$ curl http://localhost:9080/demo1
<html>
<h1> C++ blazing fast web server. </h1>
<img src='https://www.howtogeek.com/wp-content/uploads/2018/09/bin_lede.png.pagespeed.ce.cyJdjIBBg2.png' />
</html>
$ curl -v http://localhost:9080/demo1
* Trying ::1...
* TCP_NODELAY set
* connect to ::1 port 9080 failed: Connection refused
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 9080 (#0)
> GET /demo1 HTTP/1.1
> Host: localhost:9080
> User-Agent: curl/7.59.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: CeePlusPlusWebServer
< Connection: Keep-Alive
< Content-Length: 279
<
<html>
<h1> C++ blazing fast web server. </h1>
<img src='https://www.howtogeek.com/wp-content/uploads/2018/09/bin_lede.png.pagespeed.ce.cyJdjIBBg2.png' />
</html>
* Connection #0 to host localhost left intact
Server route: /file
- Http request to URL:
http://localhost:9080/file
$ curl http://localhost:9080/file # /etc/protocols: # $Id: protocols,v 1.12 2016/07/08 12:27 ovasik Exp $ # # Internet (IP) protocols # # from: @(#)protocols 5.1 (Berkeley) 4/17/89 # # Updated for NetBSD based on RFC 1340, Assigned Numbers (July 1992). # Last IANA update included dated 2011-05-03 # # See also http://www.iana.org/assignments/protocol-numbers ip 0 IP # internet protocol, pseudo protocol number hopopt 0 HOPOPT # hop-by-hop options for ipv6 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... hip 139 HIP # Host Identity Protocol shim6 140 Shim6 # Shim6 Protocol wesp 141 WESP # Wrapped Encapsulating Security Payload rohc 142 ROHC # Robust Header Compression # 143-252 Unassigned [IANA] # 253 Use for experimentation and testing [RFC3692] # 254 Use for experimentation and testing [RFC3692] # 255 Reserved [IANA]
1.12 Httplib - Http Client and Server Library
Cpp-Httplib is a single-file and header-only library for building HTTP client or HTTP server applications. The advantage of this library is that unlike most HTTP libraries, it does not relies on LibCurl or on Boost.ASIO which makes Cpp-Httplib easier to setup and add to new projects.
Repository:
Dependencies:
- SSL Library for HTTPS
- Or OpenSSL
- Or LibreSSL (OpenSSL fork from OpenBSD)
- Or WolfSSL (SSL for embedded applications)
- LibZ for Compression
- Pthread (Posix Threads) on Unix-like operating systems
Sample project
Gist:
File: CMakeLists.txt
cmake_minimum_required(VERSION 3.9) project(httplib-client) #========== Global Configurations =============# #----------------------------------------------# set(CMAKE_CXX_STANDARD 17) set(CMAKE_VERBOSE_MAKEFILE ON) set(CMAKE_CXX_EXTENSIONS OFF) # ------------ Download CPM CMake Script ----------------# ## Automatically donwload and use module CPM.cmake file(DOWNLOAD https://raw.githubusercontent.com/TheLartians/CPM.cmake/v0.26.2/cmake/CPM.cmake "${CMAKE_BINARY_DIR}/CPM.cmake") include("${CMAKE_BINARY_DIR}/CPM.cmake") #----------- Add dependencies --------------------------# CPMAddPackage( NAME httplib URL "https://github.com/yhirose/cpp-httplib/archive/v0.6.6.zip" ) include_directories( ${httplib_SOURCE_DIR} ) find_package(PkgConfig REQUIRED) pkg_search_module(OPENSSL REQUIRED openssl) message([TRACE] " httplib source = ${httplib_SOURCE_DIR} ") message([TRACE] " OPENSSL_LIBRARIES = ${OPENSSL_LIBRARIES} ") #----------- Set targets -------------------------------# add_executable(client client.cpp) # Requires implementation of this for Windows. IF(UNIX) target_link_libraries(client pthread z ${OPENSSL_LIBRARIES} ) ENDIF()
File: client.cpp
#include <iostream> #include <cassert> #include <functional> #include <fstream> #define CPPHTTPLIB_ZLIB_SUPPORT #define CPPHTTPLIB_OPENSSL_SUPPORT #include <httplib.h> namespace h = httplib; template<typename T> using shp = std::shared_ptr<T>; int main(int argc, char** argv) { std::cout << "\n [TRACE] Started Ok. " << "\n\n"; // -------- E X P E R I M E N T / 1 --------------------------------------// //------------------------------------------------------------------------// std::cout << " [EXPERIMENT 1] HttpS (HTTP + SSL) Request " << '\n'; std::puts(" ----------------------------------------------------"); { h::SSLClient cli("www.httpbin.org"); // cli.enable_server_certificate_verification(true); shp<h::Response> res = cli.Get("/get"); assert( res != nullptr ); if(res) { std::cout << " => Http Version = " << res->version << '\n'; std::cout << " => Status = " << res->status << '\n'; std::cout << " => Content-Type = " << res->get_header_value("Content-Type") << '\n'; std::puts(" --- All HTTP headers -----------"); for( auto const& [key, value] : res->headers ) std::cout << std::setw(40) << std::right << key << " " << std::setw(35) << std::left << value << "\n"; if(res->status == 200) std::cout << "\n [INFO] HTTP Response = " << res->body << '\n'; } } // -------- E X P E R I M E N T / 1 --------------------------------------// //------------------------------------------------------------------------// std::cout << " [EXPERIMENT 2] Https (HTTP + SSL) ==>> Download binary file " << '\n'; std::puts(" ----------------------------------------------------"); auto ifs = std::ofstream("image.jpeg"); auto cli = h::Client2("https://www.httpbin.org"); auto res = cli.Get("/image/jpeg" ,[&](const char* bytes, size_t len) -> bool { ifs.write(bytes, len); // Note: return false for stopping processing the request return true; }); // Status 200 means successful HTTP response from server. std::cout << " Res->status = " << res->status << '\n'; std::cout << "\n [TRACE] Finish Ok. " << "\n"; return 0; }
Building:
$ git clone https://gist.github.com/caiorss/d890edcb1cf3814ffcd6915940e4f2ca code && cd code
$ ls
client.cpp CMakeLists.txt
$ cmake -H. -B_build -DCMAKE_BUILD_TYPE=Debug
$ cmake --build _build --target
Check compilation output: (object code)
$ file _build/client _build/client: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=e2aa2ba8c5258b274b1c58ddd6039c2f9c83f995, for GNU/Linux 3.2.0, with debug_info, not stripped # Shared library dependencies $ ldd _build/client linux-vdso.so.1 (0x00007ffffa9cd000) libpthread.so.0 => /lib64/libpthread.so.0 (0x00007fbbbc4f5000) libz.so.1 => /lib64/libz.so.1 (0x00007fbbbc4db000) libssl.so.1.1 => /lib64/libssl.so.1.1 (0x00007fbbbc444000) libcrypto.so.1.1 => /lib64/libcrypto.so.1.1 (0x00007fbbbc157000) libstdc++.so.6 => /lib64/libstdc++.so.6 (0x00007fbbbbf67000) libm.so.6 => /lib64/libm.so.6 (0x00007fbbbbe21000) libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007fbbbbe04000) libc.so.6 => /lib64/libc.so.6 (0x00007fbbbbc3a000) /lib64/ld-linux-x86-64.so.2 (0x00007fbbbc53b000) libdl.so.2 => /lib64/libdl.so.2 (0x00007fbbbbc33000)
Running:
$ _build/client
[TRACE] Started Ok.
[EXPERIMENT 1] HttpS (HTTP + SSL) Request
----------------------------------------------------
=> Http Version = HTTP/1.1
=> Status = 200
=> Content-Type = application/json
--- All HTTP headers -----------
Access-Control-Allow-Credentials true
Access-Control-Allow-Origin *
Connection close
Content-Length 293
Content-Type application/json
Date Mon, 08 Jun 2020 17:15:26 GMT
Server gunicorn/19.9.0
[INFO] HTTP Response = {
"args": {},
"headers": {
"Accept": "*/*",
"Content-Length": "0",
"Host": "www.httpbin.org",
"User-Agent": "cpp-httplib/0.6",
"X-Amzn-Trace-Id": "Root=2-5ede733a-52cceb0745415a696bea025d"
},
"origin": "153.8.52.56",
"url": "https://www.httpbin.org/get"
}
[EXPERIMENT 2] Https (HTTP + SSL) ==>> Download binary file
----------------------------------------------------
Res->status = 200
[TRACE] Finish Ok.