



Internationalization i18n and Localization i10n concepts
Terminology of Internationalization ¶

- ISO
- International Organization for Standardization
- W3C
- World Wide Web Consortium
- IANA
- Intenet Assigned Numbers Authority
- IETF
- Internet Engineering Task Force
- AE
- American English
- BE
- British English
- i10n - Localization (AE) or Localisation (BE)
- Adaptation of software or product to meet language and culture of a particular target market ou audience. Localization is not only language translation, but also cultural adaption, inclunding, country currency, parper size ISO A4 or Letter sizer, date time format, cultural conventions, legal requirements.
- i18n - Internationalization (AE), Internationalisation (BE)
- Process of building a software application capable of adapting to multiple languages and cultures without code changing. In other words, a internationalization is the process of building a software with localization infrastructure, that allows adding new localization without code changes.
- g11n - Globalization
- Combination of internationalization and localization. This terminology is used by IBM and Oracle.
- Locale
- Language ISO code for instance, en-US (American English), en-UK (British English), fr-CA (Canadian French) and so on.
- CJK Languages
- Chinese, Japanese and Korean languages
- CJKV Languages
- Chinese, Japanese, Korean and Vietnamese languages
- RTL Languages
- Right-To-Left Languages. Languages written from right to left. Examples: most languages using Latin Script, including, English, Greek and so on.
- LTR Languages
- Left-To-Right Languages. Languages written from left to right. Example: Hebrew, Arabic, Persian, Urdu, Phoenician and so on.
- SOV word order
- Subject-Object-Verb
- SVO word order
- Subject-Verb-Object word order
- Agglutinative language
- Example: Hungarian, Turkish, Mongolian, Japanese and Korean.
- "An agglutinative language is a type of language that primarily forms words by stringing together morphemes (word parts)—each typically representing a single grammatical meaning—without significant modification to their forms (agglutinations). In such languages, affixes (prefixes, suffixes, infixes, or circumfixes) are added to a root word in a linear and systematic way, creating complex words that encode detailed grammatical information." (Wikipedia)
- NVL
- National Language Version
- ICU
- International Components for Unicode
- ICU4J
- Java implementatijon of the ICU library.
- CLDR
- Common Locale Data Repository (from ICU project)
- LMDL
- Locale Data Markup Language (XML-based language - ICU project).
- IDN
- Internationalization of Domain Names
- gTLD
- Generic top-level domains
- ccTLD
- Country code top-level domain
- ASCII
- American Standard Code for Information Interchange
- UTF-8
- Unicode 8 bits. One "character" or symbol may use more than one byte. Unicode 8 bits is the most used text enconding format possibly due to the backward compatibility with the old ASCII text encoding. However, it makes programming harder since one cannot assume that i-th position of a unicode string corresponds to the i-th character because a single UTF-8 "character" may be represented by multiple bytes.
- UTF-16
- Unicode 16 bits. One "character" or symbol is represented by 2 bytes. The UTF-16 encoding is mostly used internally by programming languages implementations, including Java and Python. The Windows C API - Application Programming Interface also uses UTF-16 in its internal APIs. This text enconding format is easier to deal with in programming langues because the i-th position of a unicode array is the i-th symbol.
- QA Testing
- EN - Quality Assurance Testing
- PT - Teste de Garantia de Qualidade
Internationalization Issues ¶
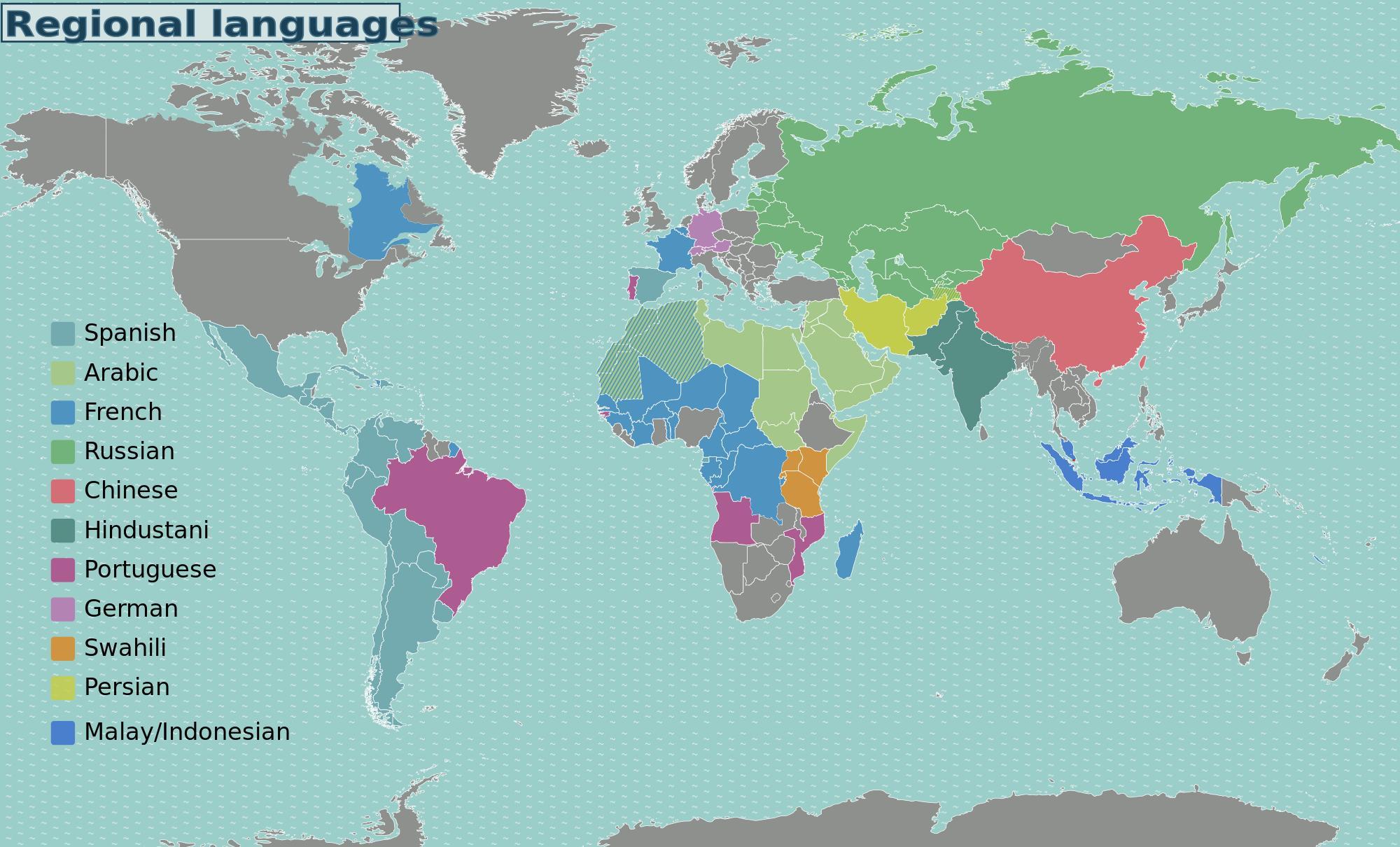
1: World Regional Languages
Brainstorm of Major Internationalization Issues
-
Initial Language
- The website or application attempts to guess the user language based on http header or IP address.
- Presents the web page in default language and provides a menu or form allowing the user to switch the language.
- Language Switching (Processo de mundança de línguagem)
-
Optimization
- Localization strings (text) served or renderend in the front-end (client side).
- Localization strigns (text) served or rendered in the backend (server side).
- Lazy loading locatization strings.
- Load only what is needed.
-
Language Issues
- Date Format
- Pluralization
- Language Dialects
- Gender-Specific Translations
- A country may have more than one language or more than one official language. For instance, in Canada, English and French are official languages and in Switzerland, German, French and Italian are official languages.
- Spelling of Specific dialect of a language (Ortografia de dialetos especificos de uma linguagem)
- RTL - Right-To-Left Language Support (Suporte a Línguagens da Esquerda para direita), for instance Arabic and Hebrew are written from right to left.
-
Cultural Issues
- Cultural Standards
- Cultural Conventions
- Cultural Assumptions
Common Mistakes ¶
- Country Flag does not represent a language. For instance, the Brazilian flag should not be used for representing the Portuguese language.
- There are more than one dialect and spelling of the same language. For instance, some words in American English and British English have different spellings, i.e internationalization (American English) and internationalisation (British English). That is the reason why country flags should not be used for representing languages.
- Localization must not only specific for a particular language. It should also be specific for each country and standardized dialect of a language, such as American English, British English, European Portuguese or Brazilian Portuguese. For instance, despite the American English be ubiuitous on the internet, most English speaking countries other than USA or Phillipines use British English spelling and languages contructs derived from this English dialect. The British English spelling is also widely used on continental Europe by non English speaking countries, including Germany, France, Portugal, Netherlands and so on.
- Do not use IP address or user geographic location for selecting the language or locale used by a website. The language should be selected based on the user preference indicated by the http header Accept-Language and the graphicsuser interface should always have a button or selection box allowing the user to switch the language. On Linux Desktop applications, the environment variable LANG is commonly used for obtaining the user desired language. This variable is set during Linux installation of Linux desktop distributions to the language chosen by the user.
- Some reasons to avoid using IP address, geographic location or country for choosing the UI - User Interface language are: some countries may have multiple official languages or multiple spoken languages; nowadays, people travels and may not be able speak the local language; even a native speakers may not want read in his or her own native language.
Common Locales ¶
ISO Language Code ¶
| Language Code | Language Name |
|---|---|
| la | Latin |
| scn | Sicilian[1] |
| it | Italian |
| es | Spanish |
| pt | Portuguese |
| fr | French |
| en | English |
| de | German |
| el | Modern Greek |
| tr | Turkish |
| sv | Swedish |
| af | Afrikaans |
| uk | Ukranian |
| sw | Swahilli |
| ja | Japanese |
| zh | Chinese |
| ko | Korean |
| vi | Vietnamese |
| hi | Hindi |
| tm | Tamil |
| pa | Punjabi |
| sa | Sanskrit |
| tg | Tajik[2] |
| id | Indonesian |
| ms | Malay |
| tl | Tagalog (Phillipines) |
| fil | Filipino (Phillipines) |
| ga | Irisih Gaelic |
| gd | Scottish Gaelic |
| gl | Galician[3] |
| ca | Catalan[4] |
| eu | Basque (Euskera) |
Locale Code ¶
Locale codes follow the convention <language-code>-<countery-code> with (-) dash character or <language-code>_<country-code> with the underline character (_).
| Country | Locale Code | Language Name |
|---|---|---|
| USA | en-US | American/USA English |
| UK | en-UK | British English (UK - United Kingdom) |
| Ireland | en-IE | Irish English |
| Ireland | ga-IE | Irish language (Irish Gaelic) |
| Canada | en-CA | Canadian English |
| Canada | fr-CA | Canadian French (Français Canadien) |
| Australia | en-AU | Australian English |
| New Zealand | en-NZ | New Zealand English |
| Singapore | en-SG | Singaporean English |
| Hong Kong | en-HK | Hong Kong English |
| South Africa | en-ZA | South African English |
| South Africa | af-ZA | Afrikaans[5] |
| Phillipines | en-PH | Phillipines English[6] |
| India[7] | en-IN | English (India) |
| India | hi-IN | Hindi[8] (India) |
| India | ta-IN | Tamil (India) |
| India | kok-IN | Konkani (India)[9] |
| India | tel-IN | Telugu (India) |
| Germany | de-DE | German (Deutsch) |
| Austria | de-AT | Austrian German (Österreichisches Deutsch) |
| Switzerland | de-CH | Switzerland German (Schweizerdeutsch) |
| Switzerland | fr-CH | Switzerland French (Suisse français) |
| Switzerland | it-CH | Switzerland Italian |
| France | fr-FR | French (Français) |
| Italy | it-IT | Italian (Italiano) |
| Greece | el-GR | Modern Greek |
| Türkiye | tr-TR | Turkish[10] |
| Cyprus | el-CY | Modern Greek of Cyprus |
| Cyprus | tr-CY | Turkish language (Cyprus) |
| Spain | es-ES | Spanish (Español) |
| Spain | ca-ES | Catalan (Catalán in Spanish) |
| Spain | eu-ES | Basque (Euskera)^{Non indo-european language} |
| Spain | gl-ES | Galician[11] |
| Mexico | es-MX | Mexican Spanish (Español mexicano)[12] |
| USA | es-US | American/USA Spanish |
| Puerto Rico | es-PR | Puerto Rico Spanish (USA) |
| Argentina | es-AR | Argentinian Spanish (Español argentino) |
| Uruguay | es-UY | Uruguayian Spanish (Español uruguayo) |
| Chile | es-CL | Chilean Spanish (Español chileno) |
| Colombia | es-CO | Colombian Spanish (Español colombiano) |
| Peru | es-PE | Peruvian Spanish (Español peruano) |
| Ecuador | es-EC | Ecuadorian Spanish (Español ecuatoriano) |
| Panama | es-PA | Panamenian Spanish (Español panameño) |
| Venezuela | es-VE | Venezuelan Spanish (Español venezolano) |
| Portugal | pt-PT | European Portuguese (Português Europeu) |
| Angola | pt-AO | Portuguese (Angola) |
| Capte Verde | pt-CV | Portuguese (Português de Cabo Verde) |
| Brazil | pt-BR | Brazilian Portuguese (Português Brasileiro) |
| Japan | ja-JP | Japanese language |
| Singapore | zh-SG | Chinese (Singapore) |
| Taiwan | zh-TW | Taiwan Chinese |
| Hong Kong | zh-HK | Hong Kong Chinese |
| China | zh-CN | Chinese (Mandarin Chinese of Mainland China) |
NOTE:
- Most English variants around the world are based on the British English and uses the British spelling. The American English spelling is only used by USA and Phillipines.
- India does not have any national language. Hindi is neither the national language of India nor the single official language of the country. Moreover, the majority of Indian population does not speak Hindi.
- Hong Kong is not country. It is a SAR - Special Administrative Region of mainland China. Hong Kong has its own currency and onlympic team. In addition, in sports matches Hong Kong uses its own flag.
- Puerto Rico is not a country. The island is USA non incorporated territory, even though the island has its own olympic team.
- Spanish locales don't have much difference other than country code, currency and paper size since most Spanish countries follows the Royal Spanish Academy[13]
Change User Interface Language on Linux
It is possible to change the UI interface language of some application on Linux on command line by setting the environment variable LANG to the desired locale code. The default system locale on Linux can be obtained by reading the environment variable $LANG.
In bash shell or any other POSIX shell.

$ echo $LANG
en_US.UTF-8
In Python,
>>> import os
>>> os.getenv("LANG", "")
'en_US.UTF-8'
The following command temporarily changes the Kwrite KDE text editor language to Swiss German even if the default language used during the Linux distribution installation was not German. This feature is useful for learning new vocabulary of other languages.
env LANG=de_CH kwrite
Lanch kwite with language set to Swiss German detached from terminal (without blocking the terminal emulator).
$ env LANG=de_CH.UTF-8 kwrite 1> /dev/null 2> /dev/null & disown
Explanation:
-
1> /dev/nullredirects the kwrite process' stdout (standard output) to Linux pseudo file /dev/null. -
2> /dev/nullredirects the kwrite process' stderr (standard error output) to Linux pseudo file /dev/null. -
& disown=> Detach kwrite process from the terminal in order run this application as a daemon (background process/service) and to avoid blocking the terminal emulator and terminating the kwrite process if the terminal is closed.
Screenshot of KWrite using different locales
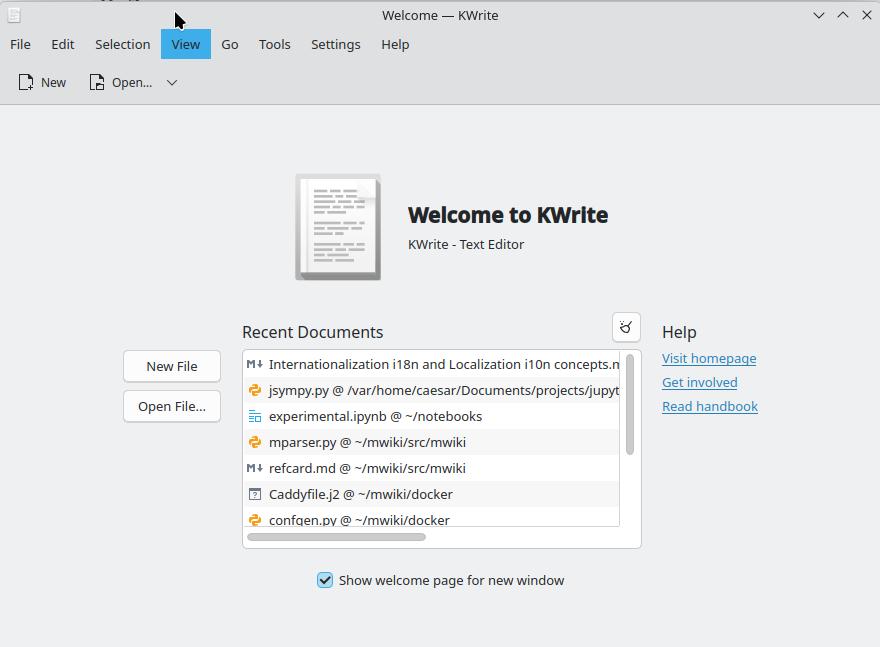
2: KWrite started with en_US American English locale
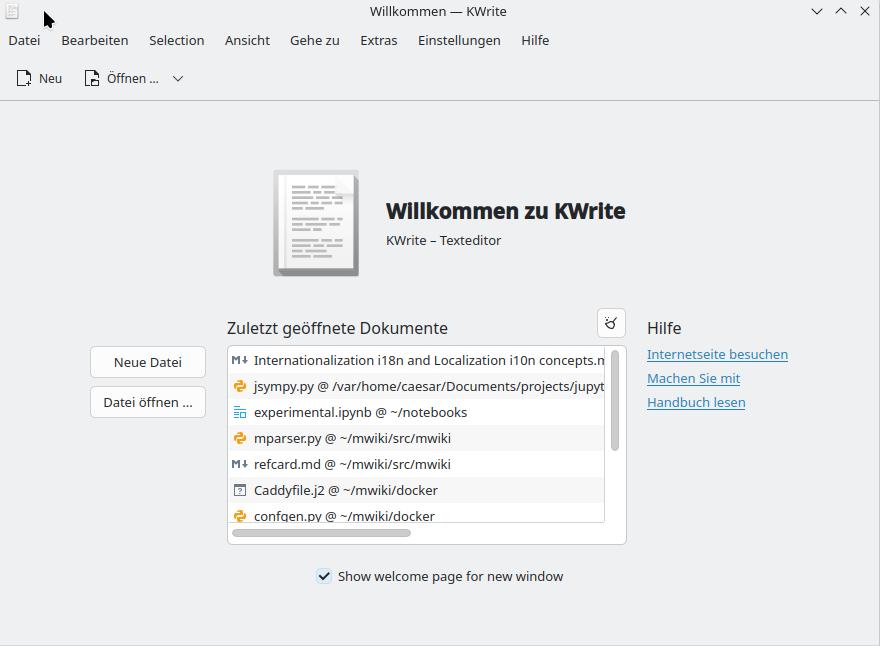
3: KWrite started with de_DE German locale for Switzerland
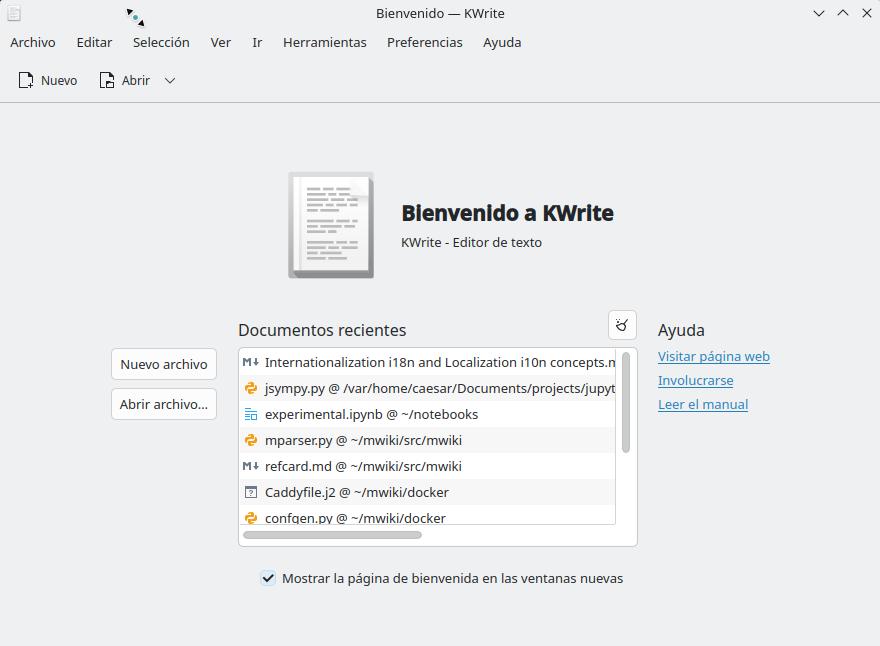
4: KWrite started with es_ES Spanish locale for Spain
See Also ¶
- Country Code Language List
- ISO-3166 Country Codes and ISO-639 Language Codes, Oracle Docs
- Standard locale names, Microsoft
- ISO Country and Language Codes: The Definitive Guide
Falsehoods Many Programmers Believe About Names ¶
- Names are only written using ascii characters. Counterexample: "João" (portuguese version of John) or " Björk" (Icelandic given name).
- Names does not contain hyphen (-) or apostrophe (') characters. Counterexample: O'Neill - common irish surname.
- A person may have only two names, a given name and surname (family name). Counterexample: the full name of Brazil's emperor Pedro II of Brazil was "Pedro de Alcântara João Carlos Leopoldo Salvador Bibiano Francisco Xavier de Paula Leocádio Miguel Gabriel Rafael".
- People do not change their names, surnames or email.
- People will never have identical names.
- The name or surname has at least 3 characters. Counterexample: "Wu".
- The full name is limited to 100 characters length.
- I will never need to deal with foreign names in my database.
- Names with the same spelling are always written in the same way with the same spelling. Counterexample: There are several different Japanese names that sounds as "Akira" and are romanized (written in latin script) as that, although they are written using different Kanji symbols and have different meanings.
- People have at least one surname. Countereraxmple: In some countries, such as Indonesia and Japan some people may have a single given name and no surname. Members of Japanese royalty do not have surnames or family names. Sukarno, the first president of Indonesia did not have any surname. His full name was just "Sukarno".
- People only a have a single given name and there is no whitespace within a given name. Counterexample: Hector Marίa GONZALEZ LÓPEZ. The given name is "Hector Marίa". The patronymic surname is Gonzalez and the mather's family name is López. Many Spanish given names have the suffix Maria in compound given names. Female hispanic given often have the suffix "de dolores", "soledad" and etc.
See also:
-
Personal names around the world, W3C
- https://www.w3.org/International/questions/qa-personal-names
- How do people's names differ around the world, and what are the implications of those differences on the design of forms, databases, ontologies, etc. for the Web?
- Legal name, Wikipedia
- Middle name, Wikipedia
- Name change, Wikipedia
- Surname, Wikipedia
- Maiden and married names, Wikipedia
- Patronymic surname, Wikipedia
- A basic guide to using Asian names, Asia Media Centre
- Chinese Naming Conventions - Chinese Culture, Cultural Atlas
- Japanese Naming Conventions - Japanese Culture, Cultural Atlas
- Wikipedia:Naming conventions (Chinese)
- East Slavic name, Wikipedia
- Naming Conventions - Russian Culture, Cultural Atlas
- Russian names, Just Russian
- Roman naming conventions, Wikipedia
- Nomen gentilicium, Wikipedia
- Cognomen, Wikipedia
- Praenomen, Wikipedia
- Italian name, Wikipedia
-
Portuguese name, Wikipedia
- https://en.wikipedia.org/wiki/Portuguese_name
- A Portuguese name, or Lusophone name – a personal name in the Portuguese language – is typically composed of one or two personal names, the mother's family surname and the father's family surname (rarely only one surname, sometimes more than two). For practicality, usually only the last surname (excluding prepositions) is used in formal greetings.
- Spanish naming customs, Wikipedia
- Spanish Names: A Beginner’s Guide to Naming Customs and Traditions, ESLZubzz
- Spanish proper names and their cultural secrets: More than just a name, WOrldsAcross
- Naming - Spanish Culture, Cultural Atlas
- Naming customs of Hispanic America, Wikipedia
- Arabic name, Wikipedia
- How Arabic Names Work: A Guide to Ism, Nasab, Laqab, Nisba, and Kunya
- Türkiye Naming Customs, Family Search
- Turkish name, Wikipedia
- Naming - Turkish Culture, Cultural Atlas
- Mononym, Wikipedia (People with no surname, just a single name)
- List of legally mononymous people, Wikipedia (List of people whose full legal name does not have surname or family name such as members of Japanese royal family)
- O'Neill (surname), Wikipedia
- Akira (given Japanese name), Wikipedia
- Category:Compound given names, Wikipedia
- How do I correctly abbreviate compounded first name for academic publications?, Academia
American English Vs British English ¶
| American English | British English |
|---|---|
| internalization | internationalisation |
| localization | localisation |
| meter[14] | metre[15] |
| meters | metres |
| program | programme |
| computer program | computer programme |
| study program | study programme |
| license | licence |
| software license | software licence |
| free software license | free software licence |
| center | centre |
| center of mass | centre of mass |
| aerodynamic center | aerodynamic centre |
| color | colour |
| favor | favour |
| favorite | favourite |
| labor | labour |
| lawyer, attorney | lawyer, barrister |
| defense | defence |
| ofense | ofence |
| shop | shoppe |
| shopping mall, mall, shopping center | shopping centre |
| tires | tyres |
| while | while, whilst |
| football | American football |
| soccer | football |
| football player | American football player |
| soccer player | football player |
| football stadium | American football stadium |
| soccer stadium | football stadium |
| football match | American football match |
| soccer match | football match |
| roommates | roommates, flatmates |
| fall | autumn |
| man, guy, dude | bloke |
| men, guys, dudes | blokes |
| bonkers | crazy |
| It is bonkers. | It is crazy. |
| friends | friends or mates |
| buddies (male friends of a guy) | lads |
| girlfriends | female friends of a woman |
| college student | university student |
| college kids | undergraduate university students (pejorative, slang) |
| freshman student | first-year undergraduate student |
| sophomore student | second-year undergraduate student |
| junior student | third-year undegraduate student (university student) |
| senior student | university student in final year of undegraduate degree |
| apartment | flat |
| truck | lorry |
| truck | shorthand for pickup truck |
| highway, freeway | motorway |
| gas station | petrol station |
Software Libraries ¶
JavaScript
- i18Next
Python
- Gettext
Footnotes ¶
[1] Closest languge to Latin.
[2] Dialect of Persian
[3] Closest language to Portuguese. Note that Galicia is now an autonomous region of Spain.
[4] Language of Catalonia region of Spain.
[5] It is based on te Dutch language with some words borrowed from other African languages.
[6] Based on American English
[7] India is among the fastest growing economies in the world. On the long run, it means higher return on investment.
[8] Hindustani
[9] Goa state, former Portuguese colony.
[10] The country is formely known as Turkey. The country's government and TRT World media have asked the world to use the name Türkiye instead of the old name, Turkey.
[11] Sister language of Portuguese
[12] Pronouce: Espanhol merricano
[13] Spanish: Real Academia Española
[14] Preferred spelling in American English
[15] Preferred spelling in British English
See also ¶
Unicode ¶
-
Punycode, Wikipedia
- https://en.wikipedia.org/wiki/Punycode
- Punycode is a representation of Unicode with the limited ASCII character subset used for Internet hostnames. Using Punycode, host names containing Unicode characters are transcoded to a subset of ASCII consisting of letters, digits, and hyphens, which is called the letter–digit–hyphen (LDH) subset. For example, the German München (English: Munich) is encoded as Mnchen-3ya. While the Domain Name System (DNS) technically supports arbitrary sequences of octets in domain name labels, the DNS standards recommend the use of the LDH subset of ASCII conventionally used for host names, and require that string comparisons between DNS domain names should be case-insensitive. The Punycode syntax is a method of encoding strings containing Unicode characters, such as internationalized domain names (IDNA), into the LDH subset of ASCII favored by DNS. It is specified in IETF Request for Comments 3492.[1]
-
Emoji domain, Wikipedia
- https://en.wikipedia.org/wiki/Emoji_domain
- An emoji domain is a domain name with one or more emoji in it, for example 😉.tld.
-
Internationalized domain name, Wikipedia
- https://en.wikipedia.org/wiki/Internationalized_domain_name
- An internationalized domain name (IDN) is an Internet domain name that contains at least one label displayed in software applications, in whole or in part, in non-Latin script or alphabet[a] or in the Latin alphabet-based characters with diacritics or ligatures.[b] These writing systems are encoded by computers in multibyte Unicode. Internationalized domain names are stored in the Domain Name System (DNS) as ASCII strings using Punycode transcription. The DNS, which performs a lookup service to translate mostly user-friendly names into network addresses for locating Internet resources, is restricted in practice[c] to the use of ASCII characters, a practical limitation that initially set the standard for acceptable domain names. The internationalization of domain names is a technical solution to translate names written in language-native scripts into an ASCII text representation that is compatible with the DNS. Internationalized domain names can only be used with applications that are specifically designed for such use; they require no changes in the infrastructure of the Internet.
- IDN homograph attack, Wikipedia
- IDN Display Algorithm, Mozilla Wiki
- UTF-8, Explained Simply, Nic Baker - Youtube Video
- "The History of UTF-8, as told by Rob Pike" (2003)
- "The History of UTF-8, as told by Rob Pike" (2003)
- Be aware of sorting locales, Adrian Stoll
-
locale(7) — Linux manual page
- https://man7.org/linux/man-pages/man7/locale.7.html
- A locale is a set of language and cultural rules. These cover aspects such as language for messages, different character sets, lexicographic conventions, and so on. A program needs to be able to determine its locale and act accordingly to be portable to different cultures.
- Iterating strings and manually decoding UTF-8, Zylinski
- Python's splitlines does a lot more than just newlines, yossarian.net
-
The Country That Broke Kotlin, Sam Cooper
- https://sam-cooper.medium.com/the-country-that-broke-kotlin-84bdd0afb237
- Logic vs language: how a Turkish alphabet bug played a years-long game of hide-and-seek inside the Kotlin compiler.
-
Does Your Code Pass The Turkey Test?, Moserware (2008)
- https://www.moserware.com/2008/02/does-your-code-pass-turkey-test.html
- Over the past 6 years or so, I’ve failed each item on “The Turkey Test.” It’s very simple: will your code work properly on a person’s machine in or around the country of Turkey? Take this simple test.
- SMS Turkish Disaster
-
Strcasecmp in Turkish, Daniel Stenberg (2008) - Curl Project
- https://daniel.haxx.se/blog/2008/10/15/strcasecmp-in-turkish/
- A friendly user submitted the (lib)curl bug report 2154627 which identified a problem with our URL parser. It doesn’t treat “file://” as a known protocol if the locale in use is Turkish.
-
Internationalization for Turkish: Dotted and Dotless Letter "I", I18nGuy
- http://www.i18nguy.com/unicode/turkish-i18n.html
- Many software and web applications that are already internationalized and are successfully supporting many languages, often suffer catastrophic failure when they add support for the Turkish language. This page explains the difficulty of supporting the Turkish language and typical solutions. There are 3 sections: A brief overview of Turkish characters and encodings. Turkish language problem and solutions. A brief history of the Turkish language is offered as background material.
- Locale-agnostic case conversions by default
Internationalization and Localization Reading ¶
- Internationalization and localization, Wikipedia
-
International Components for Unicode, Wikipedia
- https://en.wikipedia.org/wiki/International_Components_for_Unicode
- International Components for Unicode (ICU) is an open-source project of mature C/C++ and Java libraries for Unicode support, software internationalization, and software globalization. ICU is widely portable to many operating systems and environments. It gives applications the same results on all platforms and between C, C++, and Java software. The ICU project is a technical committee of the Unicode Consortium and sponsored, supported, and used by IBM and many other companies.[2] ICU has been included as a standard component with Microsoft Windows since Windows 10 version 1703.[3]
-
Declaring language in HTML, W3C (2021)
- https://www.w3.org/International/questions/qa-html-language-declarations
- How should I set the language of the content in my HTML page? This page describes how to mark up an HTML page so that it gives information about the language of the page. It begins with an overall summary, then provides additional details in subsequent sections.
-
Types of language declaration, W3C (2019)
- https://www.w3.org/International/questions/qa-text-processing-vs-metadata
- On the Web it is always important to associate content with language information. This is important on the one hand so that content can be processed or presented correctly to the reader, but on the other, it may also be important to know the language(s) of the intended audience for the resource as a whole. These are two different things: technologies should provide separate ways of expressing each, and content authors should use those appropriately. This article describes how these two types of language information, ('metadata' and 'text-processing') differ.
-
HTTP headers, meta elements and language information, W3C Interantionalization
- https://www.w3.org/International/questions/qa-http-and-lang
- In addition to the lang (and/or xml:lang) attribute on the html tag, you may come across language information in HTML meta elements, or in the HTTP header which is served with an HTML page. Here we look at whether these are useful when declaring language for HTML content, and if so, how they should be used. This article is (specifically) about language declarations in HTTP headers and meta elements. It's not a general guide to setting language on an HTML page: for that, see Declaring language in HTML. This article builds on the distinction between (1) using file metadata to identify the audience for the document, and (2) specifying the language used for the purpose of processing content. If you want to better understand the distinction see the article Types of language declaration.
-
Internationalization techniques: Authoring web pages, W3C
- https://www.w3.org/International/techniques/authoring-html?open=language&open=primarylanguage#primarylanguage
- This page lists links to resources on the W3C Internationalization Activity site and elsewhere that help you author HTML and CSS for internationalization. You are not expected to read this page from top to bottom. Instead, select topics of interest from the control just below. You can see a list of updates to this document. You can also raise an issue about this page.
- ICU-TC Home Page
-
Unicode CLDR Project
- https://cldr.unicode.org/
- The Unicode Common Locale Data Repository (CLDR) provides key building blocks for software to support the world’s languages with the largest and most extensive standard repository of locale data available. This data is supplied by contributors for their languages via the CLDR SurveyTool. CLDR is used by a wide spectrum of companies for their software internationalization and localization, adapting software to the conventions of different languages for such common software tasks. It includes: Locale-specific patterns for formatting and parsing: dates, times, timezones, numbers and currency values, measurement units,… Translations of names: languages, scripts, countries and regions, currencies, eras, months, weekdays, day periods, time zones, cities, and time units, emoji characters and sequences (and search keywords),… Language & script information: characters used; plural cases; gender of lists; capitalization; rules for sorting & searching; writing direction; transliteration rules; rules for spelling out numbers; rules for segmenting text into graphemes, words, and sentences; keyboard layouts… Country information: language usage, currency information, calendar preference, week conventions,… Validity: Definitions, aliases, and validity information for Unicode locales, languages, scripts, regions, and extensions,…
- Language Plural Rules, ICU Project
- ICU4J Readme, ICU Documentation (Java implementation of ICU Library)
- Formatting Messages, ICU Documentation
- A complete guide to ICU message format & syntax with examples, Llya Kurowski (2024)
-
ICU message format: Guide to plurals, dates & localization syntax, Kinga Pomkala (2023), SimpleLocalize
- https://simplelocalize.io/blog/posts/what-is-icu/
- ICU message format is the standard way developers handle plurals, dates, numbers, and other localized text in software. It's part of the internationalization (i18n) toolkit that ensures your messages are grammatically correct, culturally accurate, and easy to translate, no matter the language or region. By using ICU, you can avoid common localization bugs like “1 rooms” or incorrect date formats, while keeping translations consistent across all platforms. Used by Google, Microsoft, and countless frameworks like React Intl and Angular, ICU allows you to define all variations of a message in one place, making life easier for both developers and translators.
-
International Components for Unicode APIs, IBM (2022)
- https://www.ibm.com/docs/en/i/7.5.0?topic=category-international-components-unicode-apis
- The International Components for Unicode (ICU), IBM® i option 39, is a C and C++ library that provides Unicode services for writing global applications in ILE programming languages. ICU offers flexibility to extend and customize the supplied services, which include: ...
-
The Ultimate Guide to ICU Message Format, Crowdin Blog (2022)
- https://crowdin.com/blog/2022/04/13/icu-guide
- What Does ICU Stand for? As ICU documentation states, ICU means International Components for Unicode – a widely used set of C/C++ and Java libraries providing Unicode and globalization support for software and applications. ICU is released under a nonrestrictive open source license that is suitable for use with both commercial software and open source or free software.
- Finally Doing Pluralization Right How the ICU plural syntax works, Alan Allegret (2021)
- A Practical Guide to the ICU Message Format, Mohamed Ashour (2025), Phrase
-
DOM Localization Proposal by Mozilla, Mozilla
- https://github.com/mozilla/explainers/blob/main/dom-localization.md
- Users of the web are best served by being able to experience it in their native languages. Currently, localization of web content is achieved with a multitude of custom solutions, most of which are unable to express the full depth and breadth of human expressions in all languages. Introducing an easy-to-use but powerful standard localization solution would improve the experience of all users, in particular the vast majority who do not speak English natively. Most localizable content is composed of simple strings, and most of the content that has some dependency on input variables only uses them as unmodified placeholders. This has lead to most localization systems having been built up iteratively, only conservatively adding new features when the need for them has been identified. Many localization systems used on the web do not support any variance in message patterns, and the ones that do almost all limit that variance to plurals, i.e. allowing for patterns like "1 thing" and "3 things" to be separately expressed. Defining a holistic and complete standard solution for the localization of the web would allow for developers to not need to pick from a number of less capable localization systems, and for existing libraries and frameworks to start using the standard solution internally.
-
Unicode and internationalization support, Android API Docs
- https://developer.android.com/guide/topics/resources/internationalization
- Android leverages the ICU library and CLDR project to provide Unicode and other internationalization support. This page's discussion of Unicode and internationalization support is divided into two sections: Android 6.0 (API level 23) and lower, and Android 7.0 (API level 24) and higher.
- Java Localization – Formatting Messages, Baeldung
- Tutorial on Python i18n: How to Use Gettext Python Module, Crowdin Blog (2022)
- Localization as code: a composable approach to localization, Matt Owen (2025) - Pharse
- 10 UI Localization Best Practices for Developers, Nimrod Kramer (2024)
-
Introduction, I18N Next Documentation
- https://www.i18next.com/
- i18next is an internationalization-framework written in and for JavaScript. But it's much more than that! i18next goes beyond just providing the standard i18n features such as (plurals, context, interpolation, format). It provides you with a complete solution to localize your product from web to mobile and desktop.
-
Personal names around the world, W3C
- https://www.w3.org/International/questions/qa-personal-names
- How do people's names differ around the world, and what are the implications of those differences on the design of forms, databases, ontologies, etc. for the Web?
- Implementing UI translation in SumatraPDF, a C++ Windows application, Kowalcyzky.info
- Internationalization and Localization in Flask Apps, Reintech Media
- The Flask Mega-Tutorial, Part XIII: I18n and L10n, Miguel Grinberg
-
How to Internationalize Your Flask App Like a Pro, Oksana Tkach - Metamova
- https://medium.com/@oksanatkach/how-to-internationalize-your-flask-app-like-a-champ-e57535185893
- How to tweak the Babel library for large i18n projects to enable pseudotranslation and iterative localization
- Localization vs. Internationalization, W3C
- Mastering Localisation (l10n) and Internationalisation (i18n) in Modern Frontend Development, Nitin Mangrule
-
GNU gettext Manual
- https://www.gnu.org/software/gettext/manual/gettext.html
- This manual documents the GNU gettext tools and the GNU libintl library, version 0.26.
-
GNU gettext, GNU Project
- https://www.gnu.org/software/gettext/
- Brief: * Usually, programs are written and documented in English, and use English at execution time for interacting with users. This is true not only from within GNU, but also in a great deal of proprietary and free software. Using a common language is quite handy for communication between developers, maintainers and users from all countries. On the other hand, most people are less comfortable with English than with their own native language, and would rather be using their mother tongue for day to day's work, as far as possible. Many would simply love seeing their computer screen showing a lot less of English, and far more of their own language. GNU gettext is an important step for the GNU Translation Project, as it is an asset on which we may build many other steps. This package offers to programmers, translators, and even users, a well integrated set of tools and documentation. Specifically, the GNU gettext utilities are a set of tools that provides a framework to help other GNU packages produce multi-lingual messages. These tools include a set of conventions about how programs should be written to support message catalogs, a directory and file naming organization for the message catalogs themselves, a runtime library supporting the retrieval of translated messages, and a few stand-alone programs to massage in various ways the sets of translatable strings, or already translated strings. A special GNU Emacs mode also helps interested parties in preparing these sets, or bringing them up to date.*
-
Guide to the ECMAScript Internationalization API, W3C Interationalization
- https://w3c.github.io/i18n-drafts/articles/intl/index.en.html
- For years, developers relied on JavaScript libraries, string manipulation, or server-side logic to ensure that users around the world see dates, numbers, and text formatted in a way that is natural and correct for them. These solutions, while functional, often added significant weight to web pages and created maintenance challenges. Fortunately, modern browsers now have a built-in, standardized solution: the ECMAScript Internationalization API, available globally in JavaScript via the Intl object. This API provides a native way to handle locale- and culture-sensitive data and operations, ensuring your application speaks your user's language correctly and efficiently. This article will serve as a practical overview of the most essential parts of the Intl API, providing actionable examples you can use to internationalize your web applications today.
- Implement a strategy to select the language/culture for each request in a localized ASP.NET Core app, Microsft Learn - Dotnet core
-
Accept-Language header, MDN - Mozilla Development Network
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Reference/Headers/Accept-Language
- The HTTP Accept-Language request header indicates the natural language and locale that the client prefers. The server uses content negotiation to select one of the proposals and informs the client of the choice with the Content-Language response header. Browsers set required values for this header according to their active user interface language. Users can also configure additional preferred languages through browser settings. The Accept-Language header generally lists the same locales as the navigator.languages property, with decreasing q values (quality values). Some browsers, like Chrome and Safari, add language-only fallback tags in Accept-Language. For example, en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7 when navigator.languages is ["en-US", "zh-CN"]. For privacy purposes (reducing fingerprinting), both Accept-Language and navigator.languages may not include the full list of user preferences. For example, in Safari (always) and Chrome's incognito mode, only one language is listed.
- Accept-Language used for locale setting, W3C (2003)
- Accept-Language Documentation, Fastly
- Internationalization and localization, Django Docs
- Translation, Django Docs
- Localization / Internationalization
- Introduction - I18N Best Practices
- Internationalize your API, The Rest API Cookbook
- Internationaliazation, Django Rest Framework Docs
- Django Internationalization and Localization Best Practices, Codezup
- Globalization and localization in ASP.NET Core, Documentation ASP.NET Core
- Vue.js and Vue Router with Internationalization and Localization, Codez Up (2024)
- Where should I do localization (server-side or client-side)?
- Internationalization, localization, and input methods in Fuchsia
-
RFC 9839 and Bad Unicode, TBray (See RFC 9839)
- https://www.tbray.org/ongoing/When/202x/2025/08/14/RFC9839
- Unicode is good. If you’re designing a data structure or protocol that has text fields, they should contain Unicode characters encoded in UTF-8. There’s another question, though: “Which Unicode characters?” The answer is “Not all of them, please exclude some.” This issue keeps coming up, so Paul Hoffman and I put together an individual-submission draft to the IETF and now (where by “now” I mean “two years later”) it’s been published as RFC 9839. It explains which characters are bad, and why, then offers three plausible less-bad subsets that you might want to use. Herewith a bit of background, but…
-
A step-by-step guide to effective website localization, Webflow
- https://webflow.com/blog/website-localization
- Discover the benefits of website localization and learn how to modify your content and marketing strategy to cater to local audiences effectively.
- Internationalization And Localization For Static Sites, Sam Richard, Smash Magazine (2020)
- Building a Multilingual Static Website: A Step-by-Step Guide, Noha Nabil (2023)
-
Internationalization, NextJS
- https://nextjs.org/docs/app/guides/internationalization
- Next.js enables you to configure the routing and rendering of content to support multiple languages. Making your site adaptive to different locales includes translated content (localization) and internationalized routes.
-
Integrating Localization Into Design Systems, Rebecca Hemstand and Mark Malek
- https://www.smashingmagazine.com/2025/05/integrating-localization-into-design-systems/
- Learn how two designers tackled the challenges of building a localization-ready design system for a global audience. This case study dives into how Rebecca and Mark combined Figma Variables and design tokens to address multilingual design issues, such as text overflow, RTL layouts, and font inconsistencies. They share key lessons learned and the hurdles they faced — including Figma’s limitations — along with the solutions they developed to create dynamic, scalable designs that adapt seamlessly across languages, themes, and densities. If you’re navigating the complexities of internationalization in design systems, this article is for you.
- Right-to-Left (RTL) Localization: The Definitive Guide
- k-yak / stati18n Public (2014)
GUI (Graphics User Interface), UX (User Experience) and Culture ¶
- How QR code payment blew up in India, Phoebe Yu - Video (Youtube)
- How Google Maps fixed India's street name problem, Phoebe Yu - Video (Youtube)
Numbers and Mesurement ¶
- International System of Units, Wikipedia
- SI base unit, Wikipedia
- SI derived unit, Wikipedia
- Decimal separator, Wikipedia
- Number formatting in Europe vs. the U.S.
- Hindu–Arabic numeral system, Wikipedia
- Arabic numerals, Wikipedia
- Eastern Arabic numerals, Wikipedia
- Indian numbering system, Wikipedia
- Chinese numerals, Wikipedia
- Japanese numerals, Wikipedia